
安装
安装官方仓库
首先必须用浏览器访问 MySQL 的 官方仓库,在对应的平台下面可以看到诸如 (mysql80-community-release-el7-1.noarch.rpm) 这样的文件名,将其替换到下面的命令中进行下载。
$ sudo wget https://dev.mysql.com/get/mysql80-community-release-el7-1.noarch.rpm
最好进行一下校验:
$ md5sum mysql80-community-release-el7-1.noarch.rpm
将校验码与网页上的对照。
安装 MySQL 官方仓库:
$ sudo rpm -ivh mysql80-community-release-el7-1.noarch.rpm
安装 MySQL
正式安装 MySQL Server:
$ sudo yum install mysql-server
提取 root 临时密码
启动后,会为 root 用户随机产生密码:
$ sudo grep 'temporary password' /var/log/mysqld.log
安全处理
$ sudo mysql_secure_installation
包括 root 密码、移除匿名用户、禁止 root 远程登陆、移除测试数据库、重载用户权限表。
启动守护进程
$ sudo systemctl enable mysqld
$ sudo systemctl start mysqld
登陆,修改 root 密码
用临时密码登陆
$ mysql -u root -p
修改 root 密码
> ALTER USER 'root'@'localhost' IDENTIFIED BY 'NEWPASSWORD';
复制
一主多从,主失效,提升从为主
- 查看 所有从服务器的复制 位置:
SHOW SLAVE STATUS返回的结果中查看Master_Log_Pos,选择最新的做为新主 - 让所有从把 中继日志执行完毕
- 新主 停止做从:在新主上执行
STOP SLAVE - 新主 启用二进制日志:修改
my.cnf,启用log-bin,重启 mysql - 把新主 从其原主断开:执行
CHANGE MASTER TO及RESET SLAVE - 记录新主的 二进制日志坐标:用
SHOW MASTER STATUS - 所有从 指向新主:所有从上运行
CHANGE MASTER TO命令,指向新主,使用上一步记下来的坐标
备份
mysqldump
mysql自带的备份工具,/usr/local/mysql/bin/mysqldump。
支持基于innodb 的热备份,但是由于是逻辑备份,所以速度不是很快,适合备份较小的数据。
mysqldump 完全备份 + 二进制日志 可以实现基于时间点的恢复。
$ mysqldump -u root -p --databases db1 db2 db3 > dump.sql
$ mysqldump -u root -p --all-databases > dump.sql
备份指定数据库
$ mysqldump -u root -p --databases dbName1 dbName2 dbName3 > backupFile.sql
备份所有数据库
$ mysqldump -u root -p --all-databases --ignore-table=mysql.user > backupServer.sql
备份指定数据库的所有表
$ mysqldump -u root -p dbName > backupFile.sql
备份指定数据库的部分表
$ mysqldump -u root -p dbName tableName1 tableName2 > backupFile.sql
恢复
mysqldump 所创建的 .sql 文件实际上是 SQL 脚本,其中包含了 CREATE TABLE、INSERT 等命令,用来重演创建表格和插入数据的操作,因此可以用来恢复数据。
用 source 命令恢复
可以在 mysql 环境中使用 source 命令来恢复。
mysql> SOURCE ~/import/backup_southwind.sql
如果备份的文件解压后有两个,分别为 *-schema.sql 和 *-data.sql,则应该先导入前者:
mysql> SOURCE ~/import/dvdrental-schema.sql
......
mysql> SOURCE ~/import/dvdrental-data.sql
用批处理模式恢复
也可以用 mysql 客户端的批处理模式来恢复:
$ mysql -u root -p southwind < backup_southwind.sql
需要提前把空数据库建好。
使用二进制日志,进行基于时间点的恢复
可以用此方法恢复被误删的数据库。先使用一个 完全备份 进行恢复,然后再进行时间点恢复。
恢复完全备份
恢复之前由 mysqldump 做的完全备份的文件 dump.sql:
$ mysql -uroot -p database_name < dump.sql
确定当前二进制日志文件
查看所有二进制日志文件
mysql> SHOW BINARY LOGS;
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000001 | 1058 |
| mysql-bin.000002 | 178 |
| mysql-bin.000003 | 178 |
|+------------------+-----------+
3 rows in set (0.01 sec) | |
查看当前使用的二进制日志文件
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000003 | 155 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.01 sec)
刷新日志
刷新日志,以便让 MySQL 生成新的二进制日志,停止向包含误操作语句的日志中写入。
在 shell 中操作:
$ mysqladmin -uroot -p -S /data/mysql.sock flush-logs
在 mysql 客户端操作:
mysql> FLUSH LOGS;
把关键二进制日志转换为文本,进行修改
mysqlbinlog 可以把二进制日志文件中的事件,由二进制格式 转换 为文本格式,以便用来执行或查看。
把二进制日志转换为文本,并 修改:
shell> mysqlbinlog mysql-bin.000003 > tmpfile
shell> vi tmpfile
🚩 编辑文本文件,找到误操作的语句,如 DROP DATABASE,将其删除。如果有其它想要删除的,可以一并进行。
执行修改过的日志文件
如果在修改过的日志之前,有多个日志文件要依次执行:
shell> mysqlbinlog mysql-bin.000001 mysql-bin.000002 | mysql -u root -p
然后再执行修改过的日志:
shell> mysql -u root -p < tmpfile
按时间或位置执行日志
以上步骤就可以完成恢复任务了。除了以上方法,还可以先在二进制日志中查明误操作发生的时间和位置,然后用指定时间范围或位置范围来执行二进制日志。
基于时间范围来恢复:
mysqlbinlog --start-datetime="2005-04-20 10:01:00" \
--stop-datetime="2005-04-20 9:59:59" mysql_bin.000001 \
| mysql -u root -ppassword database_name
基于位置范围来恢复:
mysqlbinlog --start-position=368315 \
--stop-position=368312 mysql_bin.000001 \
| mysql -u root -ppassword database_name
监控
查看当前进程
在 shell 中查看:
$ mysqladmin processlist -uroot -p -h 127.0.0.1
Enter password:
+----+-----------------+-----------------+----+---------+-------+--------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------------+----+---------+-------+--------------------------------------------------------+------------------+
| 4 | system user | | | Connect | 20045 | Connecting to master | |
| 5 | system user | | | Query | 7947 | Slave has read all relay log; waiting for more updates | |
| 6 | event_scheduler | localhost | | Daemon | 20045 | Waiting on empty queue | |
| 17 | root | localhost:33820 | | Query | 0 | starting | show processlist |
+----+-----------------+-----------------+----+---------+-------+--------------------------------------------------------+------------------+
使用 -h 是为了通过 TCP socket 连接,以便在结果中显示连接的端口号。
在 mysql 客户端查看:
mysql> SHOW PROCESSLIST;
+----+-----------------+-----------+------+---------+-------+------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------+------+---------+-------+------------------------+------------------+
| 4 | event_scheduler | localhost | NULL | Daemon | 20110 | Waiting on empty queue | NULL |
| 8 | root | localhost | NULL | Query | 0 | starting | SHOW PROCESSLIST |
+----+-----------------+-----------+------+---------+-------+------------------------+------------------+
2 rows in set (0.00 sec)
全局
登陆 MySQL
mysql -h host -u user -p
登陆时指定数据库名称:
mysql -h host -u user -p db_name
用户管理
创建用户
CREATE USER 'hawk'@'%' IDENTIFIED BY 'password';
CREATE USER 'hawk'@'localhost' IDENTIFIED BY 'password'
CREATE USER 'hawk'@'192.168.1.101' DEFAULT ROLE administrator, developer;
CREATE USER 'hawk'@'localhost' WITH MAX_QUERIES_PER_HOUR 500 MAX_UPDATES_PER_HOUR 100;
CREATE USER 'hawk'@'localhost' PASSWORD EXPIRE INTERVAL 180 DAY;
删除用户
DROP USER 'hawk'@'localhost';
为用户分配权限
GRANT ALL ON db.* TO 'hawk'@'localhost';
GRANT ALL ON *.* TO 'hawk'@'localhost' IDENTIFIED BY ’something’ WITH GRANT OPTION;
GRANT SELECT,INSERT ON test.* TO 'hawk'@'%';
撤消用户权限
REVOKE INSERT ON *.* FROM 'hawk'@'localhost';
REVOKE 'role1', 'role2' FROM 'hawk'@'localhost', 'user2'@'localhost';
REVOKE SELECT ON world.* FROM 'role3';
为用户修改密码
SET PASSWORD FOR 'neo'@'%' = PASSWORD('password');
# 或
ALTER USER 'hawk'@'localhost' IDENTIFIED BY 'newpassword'
修改 root 密码
在 shell 中修改
使用 mysqladmin
$ mysqladmin –u root –p password "NEWPASSWORD"
回车后会提示输入旧密码。
使用 mysql_secure_installation
输入旧密码之后,会提示是否修改 root 密码,当然还会多问几个问题。
在 mysql 环境中修改
GRANT ALL ON *.* TO root@'localhost' IDENTIFIED BY 'NEWPASSWORD';
重置 root 密码
旧版
停止 mysqld 服务
$ sudo systemctl stop mysqld
启动 mysqld_safe,绕过授权表,不启动网络
$ /usr/local/mysql/bin/mysqld_safe --skip-grant-tables --skip-networking &
免密登陆 root,重置密码
$ mysql -u root
Mysql> UPDATE mysql.user SET password='NEWPASSWORD' WHERE user='root';
Mysql> FLUSH PRIVILEGES;
新版
停止 mysqld 服务
$ sudo systemctl stop mysqld
修改环境变量,启动 mysqld
如果在使用 systemd 的系统中,将不会有 mysqld_safe(因为不需要),转而使用环境变量:
$ sudo systemctl set-environment MYSQLD_OPTS="--skip-grant-tables"
$ sudo start mysqld
免密码登陆 root,清空当前密码
$ mysql -u root
在较新的版本中,mysql.user 的表结构发生了变化,不再使用 password 字段,转为使用 authentication_string 字段来保存密码,需要先将密码清空:
mysql> UPDATE mysql.user SET authentication_string=null WHERE User='root';
mysql> FLUSH PRIVILEGES;
mysql> QUIT
注意,此时不支持使用 ALTER USER 来修改密码,否则会提示:
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'NEWPASSWORD';
ERROR 1290 (HY000): The MySQL server is running with the --skip-grant-tables option so it cannot execute this statement
取消环境变量,重新免密登陆,修改密码
$ sudo systemctl stop mysqld
$ sudo systemctl unset-environment MYSQLD_OPTS
$ sudo systemctl start mysqld
$ mysqld -u root
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'NEWPASSWORD';
mysql> FLUSH PRIVILEGES;
数据定义
库操作
创建库
CREATE DATABASE db_name;
CREATE DATABASE IF NOT EXISTS southwind;
查看库的创建参数
SHOW CREATE DATABASE db_name
查看库列表
SHOW DATABASES;
配置默认库
切换到某个库,从而随后的命令都默认是针对该库进行操作的。
USE db_name;
查看默认库
查看当前默认操作哪个库。
SELECT DATABASE();
删除库
DROP DATABASE db_name
DROP DATABASE IF EXISTS southwind;
$ sudo mysqladmin -u root -p drop db_name
表操作
查看当前库中的所有表
SHOW TABLES;
查看表的结构
DESCRIBE tbl_name;
创建表
语法:
CREATE TABLE [IF NOT EXISTS] table_name(
column_list
) ENGINE=storage_engine;
其中 column_list 的语法:
column_name data_type(length) [NOT NULL] [DEFAULT value] [AUTO_INCREMENT]
范例:
新建空表
CREATE TABLE IF NOT EXISTS tasks (
task_id INT AUTO_INCREMENT,
title VARCHAR(255) NOT NULL,
start_date DATE,
due_date DATE,
status TINYINT NOT NULL,
priority TINYINT NOT NULL,
description TEXT,
PRIMARY KEY (task_id)
) ENGINE=INNODB;
CREATE TABLE IF NOT EXISTS products (
productID INT UNSIGNED NOT NULL AUTO_INCREMENT,
productCode CHAR(3) NOT NULL DEFAULT '',
name VARCHAR(30) NOT NULL DEFAULT '',
quantity INT UNSIGNED NOT NULL DEFAULT 0,
price DECIMAL(7,2) NOT NULL DEFAULT 99999.99,
PRIMARY KEY (productID)
);
从现有表创建
CREATE TABLE NewTable AS
SELECT name, age
FROM OldTable
WHERE age > 25;
原表中的数据会携带过来,相当于另存为新表。
查看表的创建参数
SHOW CREATE TABLE tbl_name \G
修改表参数
增加字段
ALTER TABLE t2 ADD COLUMN
删除字段
ALTER TABLE t2 DROP COLUMN c, DROP COLUMN d;
修改字段
ALTER TABLE tbl_name
CHANGE COLUMN old_name new_name INT(11) NOT NULL AUTO_INCREMENT;
删除表
DROP TABLE IF EXISTS tbl_name;
数据操作
本节使用的范例:假设有一个产品销售数据库,名为 southwind,其中有多个表,包括 products、cutomers、suppliers、orders、payments、employees 等。
插入行
插入一行
INSERT INTO products VALUES (1001, 'PEN', 'Pen Red', 5000, 1.23);
插入多行
INSERT INTO products VALUES
(NULL, 'PEN', 'Pen Blue', 8000, 1.25),
(NULL, 'PEN', 'Pen Black', 2000, 1.25);
插入多行,仅为特定字段赋值。
INSERT INTO products (productCode, name, quantity, price) VALUES
('PEC', 'Pencil 2B', 10000, 0.48),
('PEC', 'Pencil 2H', 8000, 0.49);
删除行
DELETE FROM products WHERE productID = 1006;
查询行
SELECT name, price FROM products;
SELECT * FROM products;
非表操作
计算
SELECT 1+1;
+-----+
| 1+1 |
+-----+
| 2 |
+-----+
1 row in set (0.00 sec)
现在时刻
SELECT NOW();
+---------------------+
| NOW() |
+---------------------+
| 2012-10-24 22:13:29 |
+---------------------+
1 row in set (0.00 sec)
同时执行多条语句
SELECT 1+1, NOW();
+-----+---------------------+
| 1+1 | NOW() |
+-----+---------------------+
| 2 | 2012-10-24 22:16:34 |
+-----+---------------------+
1 row in set (0.00 sec)
比较操作
SELECT name, price FROM products WHERE price < 1.0;
SELECT name, quantity FROM products WHERE quantity <= 2000;
SELECT name, price FROM products WHERE productCode = 'PEN';
字符串匹配
用 LIKE、NOT LIKE 进行匹配。
abc%匹配以abc开头的字符串___匹配三个字符组成的字符串a_b%匹配:以a开头,接着是一个任意字符,然后是一个b,接着是任意位的字符
SELECT name, price FROM products WHERE name LIKE 'PENCIL%';
SELECT name, price FROM products WHERE name LIKE 'P__%';
算术运算符
可以使用算术运算符进行数学计算。
| 运算符 | 说明 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| DIV | 整除 |
| % | 取余 |
逻辑运算符
可以用布尔值来组合多个条件。
SELECT * FROM products WHERE quantity >= 5000 AND name LIKE 'Pen %';
SELECT * FROM products WHERE quqntity >= 5000 AND price < 1.24 AND name LIKE 'Pen %';
SELECT * FROM products WHERE NOT (quantity >= 5000 AND name LIKE 'Pen %');
IN、NOT IN
为过滤的字段提供几个可能的备选值。
SELECT * FROM products WHERE name IN ('Pen Red', 'Pen Black');
BETWEEN、NOT BETWEEN
指定过滤字段值的范围。
SELECT * FROM products
WHERE (price BETWEEN 1.0 and 2.0) AND (quantity BETWEEN 1000 AND 2000);
IS NULL、IS NOT NULL
NULL 是个特殊的值,代表该字段没有值、值丢失或值未知。用 IS NULL 与 IS NOT NULL 可以检查该字段是否包含 NULL。
SELECT * FROM products WHERE productCode IS NULL;
ORDER BY
查询结果如何排序,默认为正序。
SELECT * FROM products WHERE name LIKE 'Pen %' ORDER BY price DESC;
SELECT * FROM products WHERE name LIKE 'Pen %' ORDER BY price DESC, quantity;
第二条是先按 price 倒序排列,其次按 quantity 正序排列(默认值)。
SELECT * FROM products ORDER BY RAND();
将查询结果,即各个行随机排序。
LIMIT
限定查询结果所显示的行数。
SELECT * FROM products ORDER BY price LIMIT 2;
仅显示头两行。
SELECT * FROM products ORDER BY price LIMIT 2, 1;
跳过前 2 行,显示之后的第 1 行,即第 3 行。
因此,如果想要查看结果中的第 10 ~ 15 行:
SELECT * FROM products ORDER BY price LIMIT 9, 6;
AS 别名
可以用 AS 来为字段名、表名定义别名,这些别名可以用来在显示结果中做为表头,也可以在命令中直接引用。
SELECT productID AS ID, productCode AS Code,
name AS Description, price AS `Unit Price` -- 定义的别名用于返回结果做为表头
FROM products
ORDER BY ID; -- 定义的别名在同一语句中可以直接引用
因为 Unit Price 中间包含空格,所以需用 反引号 括起来。
CONCAT() 函数
用该函数可以把多个字段连接在一起,在查询结果中作为一个字段显示。
SELECT CONCAT(productCode, ' - ', name) AS `Product Description`, price FROM products;
+---------------------+-------+
| Product Description | price |
+---------------------+-------+
| PEN - Pen Red | 1.23 |
| PEN - Pen Blue | 1.25 |
| PEN - Pen Black | 1.25 |
| PEC - Pencil 2B | 0.48 |
| PEC - Pencil 2H | 0.49 |
+---------------------+-------+
生成汇总报表
要想生成汇总报表,经常会需要把相关的行 合并 在一起。
DISTINCT
每个字段可能包含重复的值,可以用 DISTINCT 来去掉重复,也可以将其用于多个字段。
SELECT DISTINCT price AS `Distinct Price` FROM products;
SELECT DISTINCT price, name FROM products;
GROUP BY
用 GROUP BY 可以把多条特定字段值相同的记录拆分开来。单独使用没什么意义,通常需要与各种统计函数配合使用。
如:
SELECT * FROM products ORDER BY productCode, productID;
+-----------+-------------+-----------+----------+-------+
| productID | productCode | name | quantity | price |
+-----------+-------------+-----------+----------+-------+
| 1004 | PEC | Pencil 2B | 10000 | 0.48 |
| 1005 | PEC | Pencil 2H | 8000 | 0.49 |
| 1001 | PEN | Pen Red | 5000 | 1.23 |
| 1002 | PEN | Pen Blue | 8000 | 1.25 |
| 1003 | PEN | Pen Black | 2000 | 1.25 |
+-----------+-------------+-----------+----------+-------+
SELECT * FROM products GROUP BY productCode;
+-----------+-------------+-----------+----------+-------+
| productID | productCode | name | quantity | price |
+-----------+-------------+-----------+----------+-------+
| 1004 | PEC | Pencil 2B | 10000 | 0.48 |
| 1001 | PEN | Pen Red | 5000 | 1.23 |
+-----------+-------------+-----------+----------+-------+
每个组中只显示第一条记录。
GROUP BY + 统计函数
常用的统计函数如:COUNT、MAX、MIN、AVG、SUM、STD、GROUP_CONCAT
可以对每个组应用统计函数,以组为单位来生成汇总报表。
COUNT
COUNT(*) 会返回查询所匹配行的总数,COUNT(columnName) 仅统计指定字段非空值的数量。
SELECT COUNT(*) AS `Count` FROM products;
+-------+
| Count |
+-------+
| 5 |
+-------+
SELECT productCode, COUNT(*) AS `Total` FROM products GROUP BY productCode;
+-------------+----------+
| productCode | COUNT(*) |
+-------------+----------+
| PEC | 2 |
| PEN | 3 |
+-------------+----------+
SELECT productCode, COUNT(*) AS count
FROM products
GROUP BY productCode
ORDER BY count DESC;
+-------------+-------+
| productCode | count |
+-------------+-------+
| PEN | 3 |
| PEC | 2 |
+-------------+-------+
MAX、MIN、AVG、STD、SUM
SELECT MAX(price), MIN(price), AVG(price), STD(price), SUM(quantity)
FROM products;
+------------+------------+------------+------------+---------------+
| MAX(price) | MIN(price) | AVG(price) | STD(price) | SUM(quantity) |
+------------+------------+------------+------------+---------------+
| 1.25 | 0.48 | 0.940000 | 0.371591 | 33000 |
+------------+------------+------------+------------+---------------+
SELECT productDoce, MAX(price) AS `Highest Price`, MIN(price) AS `Lowest Price`
FROM products
GROUP BY producCode;
+-------------+---------------+--------------+
| productCode | Highest Price | Lowest Price |
+-------------+---------------+--------------+
| PEC | 0.49 | 0.48 |
| PEN | 1.25 | 1.23 |
+-------------+---------------+--------------+
SELECT productCode, MAX(price), MIN(price),
CAST(AVG(price) AS DECIMAL(7,2)) AS `Average`,
CAST(STD(price) AS DECIMAL(7,2)) AS `Std Dev`,
SUM(quantity)
FROM products
GROUP BY productCode;
+-------------+------------+------------+---------+---------+---------------+
| productCode | MAX(price) | MIN(price) | Average | Std Dev | SUM(quantity) |
+-------------+------------+------------+---------+---------+---------------+
| PEC | 0.49 | 0.48 | 0.49 | 0.01 | 18000 |
| PEN | 1.25 | 1.23 | 1.24 | 0.01 | 15000 |
+-------------+------------+------------+---------+---------+---------------+
CAST 的作用是转换数据类型。
HAVING
该子句与 WHERE 类似,但 HAVING 可以和 GROUP BY 统计函数配合使用,而 WHERE 只能进行字段操作。
SELECT
productCode AS `Product Code`,
COUNT(*) AS `Count`,
CAST(AVG(price) AS DECIMAL(7,2)) AS `Average`
FROM products
GROUP BY productCode
HAVING Count >=3;
+--------------+-------+---------+
| Product Code | Count | Average |
+--------------+-------+---------+
| PEN | 3 | 1.24 |
+--------------+-------+---------+
WITH ROLLUP
WITH ROLLUP 是对 GROUP BY 所返回的所有记录进行一个汇总。
SELECT
productCode,
MAX(price),
MIN(price),
CAST(AVG(price) AS DECIMAL(7,2)) AS `Average`,
SUM(quantity)
FROM products
GROUP BY productCode
WITH ROOLLUP;
+-------------+------------+------------+---------+---------------+
| productCode | MAX(price) | MIN(price) | Average | SUM(quantity) |
+-------------+------------+------------+---------+---------------+
| PEC | 0.49 | 0.48 | 0.49 | 18000 |
| PEN | 1.25 | 1.23 | 1.24 | 15000 |
| NULL | 1.25 | 0.48 | 0.94 | 33000 |
+-------------+------------+------------+---------+---------------+
修改数据
使用 UPDATE 语句来修改数据。
语法
UPDATE tableName SET columnName = {value|NULL|DEFAULT}, ... WHERE criteria
修改所有数据
UPDATE products SET price = price * 1.1;
修改部分记录
UPDATE products SET quantity = quantity - 100 WHERE name = 'Pen Red';
修改多个值
UPDATE products SET quantity = quantity + 50, price = 1.23 WHERE name = 'Pen Red';
删除记录
使用 DELETE FROM 语句可以从表中删除记录。
删除部分记录
DELETE FROM products WHERE name LIKE 'Pencil%';
删除全部记录
DELETE FROM products;
表中全部记录将被删除,无法恢复。
导入/导出数据
LOAD DATA LOCAL INFILE ... INTO TABLE ...
可以把原始数据保存到文本文件,然后使用 LOAD DATA 语句加载到表中。
例如保存为 .csv 文件,并用逗号分隔。
\N,PEC,Pencil 3B,500,0.52
\N,PEC,Pencil 4B,200,0.62
\N,PEC,Pencil 5B,100,0.73
\N,PEC,Pencil 6B,500,0.47
导入:
LOAD DATA LOCAL FILE '~/Documents/products_in.csv' INTO TABLE products
COLUMNS TERMINATED BY ',';
注意:
- 默认的行分隔符为
\n,如果是在 windows 中编辑的,则需使用\r\n。 - 默认的字段分隔符为 tab,如果使用其它的符号,如逗号,则需要用
COLUMNS TERMINATED BY ','来说明。 - 如果是空值,需用
\N来表示。
mysqlimport
mysqlimport 是一个工具,可用来从文本文件中导入数据。文本文件需以 .tsv 为后缀,文件名必须与表名相同。
$ mysqlimport -u root -p --local southwind ~/Documents/products.tsv
SELECT ... INTO OUTFILE ...
用该语句可以将指定数据导出为文件。
SELECT * FROM products INTO OUTFILE '~/Documents/products_out.csv'
COLUMNS TERMINATED BY ','
LINES TERMINATED BY ',';
使用 SQL 脚本
除了使用单条语句,还可以把 SQL 语句保存在一个文本文件中,称为 SQL 脚本,来运行该脚本。通常保存为 .sql 文件。
例如脚本内容为:
DELETE FROM products;
INSERT INTO products VALUES (2001, 'PEC', 'Pencil 3B', 500, 0.52),
(NULL, 'PEC', 'Pencil 4B', 200, 0.62),
(NULL, 'PEC', 'Pencil 5B', 100, 0.73),
(NULL, 'PEC', 'Pencil 6B', 500, 0.47);
SELECT * FROM products;
在 MySQL 中,使用 source 命令运行脚本 :
source ~/Documents/load_products.sql
或者在命令行中将脚本重定向,用 mysql 客户端程序的批处理模式来执行:
$ mysql -u root -p southwind < ~/Documents/load_products.sql
多表操作
suppliers 表:
| supplierID | name | phone |
|---|---|---|
| 501 | ABC Traders | 88881111 |
| 502 | XYZ Company | 88882222 |
| 503 | QQ Corp | 88883333 |
products 表:
| productID | productCode | name | quantity | price |
|---|---|---|---|---|
| 2001 | PEC | Pencil 3B | 500 | 0.52 |
| 2002 | PEC | Pencil 4B | 200 | 0.62 |
| 2003 | PEC | Pencil 5B | 100 | 0.73 |
| 2004 | PEC | Pencil 6B | 500 | 0.47 |
一对多关系
继续上例,假设每个产品有一个供应商,每个供应商有一或多个产品。创建 suppliers 表来保存供应商数据,字段为 name、address、phone number,同时创建一个可以唯一标识各家供应商的字段 supplierID,将该字段设为该表的主键,以确保唯一性及快速查询。
要想将 suppliers 与 products 表关联在一起,需要在 products 表中增加一个字段,即 supplierID,然后将其做为外键,以实现引用的完整性。suppliers 称为父表,products 为子表。
因此,这里一对多即指 父表中的一条记录,对应子表中的多条记录。它们需要通过主键和外键来进行约束,以保证引用的完整性。
USE southwind;
DROP TABLE IF EXISTS suppliers;
CREATE TABLE suppliers (
supplierID INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(30) NOT NULL DEFAULT '',
phone CHAR(8) NOT NULL DEFAULT '',
PRIMARY KEY (supplierID)
);
DESCRIBE suppliers;
+------------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+------------------+------+-----+---------+----------------+
| supplierID | int(10) unsigned | NO | PRI | NULL | auto_increment |
| name | varchar(30) | NO | | | |
| phone | char(8) | NO | | | |
+------------+------------------+------+-----+---------+----------------+
INSERT INTO suppliers VALUES
(501, 'ABC Traders', '88881111'),
(502, 'XYZ Company', '88882222'),
(503, 'QQ Corp', '88883333');
SELECT * FROM suppliers;
+------------+-------------+----------+
| supplierID | name | phone |
+------------+-------------+----------+
| 501 | ABC Traders | 88881111 |
| 502 | XYZ Company | 88882222 |
| 503 | QQ Corp | 88883333 |
+------------+-------------+----------+
ALTER TABLE
为 products 表增加一个字段 supplierID:
ALTER TABLE products
ADD COLUMN supplierID INT UNSIGNED NOT NULL;
然后,需要在子表 products 的 supplierID 字段上,增加一个到父表的 外键约束,以确保 products 表中的每个 supplierID 都会对应一个 suppliers 表中的 supplierID,这就称之为 引用的完整性。
在增加外键之前,需要为 products 现有的记录指定 supplierID,这些 supplierID 必须当前存在于 suppliers 表中。
UPDATE products SET supplierID = 501;
现在,增加外键:
ALTER TABLE products
ADD FOREIGN KEY (supplierID) REFERENCES suppliers (supplierID);
修改一条记录的供应商:
UPDATE products SET supplierID = 502 WHERE productID = 2004;
SELECT * FROM products;
+-----------+-------------+-----------+----------+-------+------------+
| productID | productCode | name | quantity | price | supplierID |
+-----------+-------------+-----------+----------+-------+------------+
| 2001 | PEC | Pencil 3B | 500 | 0.52 | 501 |
| 2002 | PEC | Pencil 4B | 200 | 0.62 | 501 |
| 2003 | PEC | Pencil 5B | 100 | 0.73 | 501 |
| 2004 | PEC | Pencil 6B | 500 | 0.47 | 502 |
+-----------+-------------+-----------+----------+-------+------------+
SELECT ... JOIN ... ON
通过两个表中共有的 supplierID 字段,可以用 SELECT ... JOIN ... ON 来联合显示两个表中相关的记录。
SELECT p.name, price, s.name
FROM products AS p
JOIN suppliers AS s ON p.supplierID = s.supplierID
WHERE p.price < 0.6;
多对多
如果此例中,一种产品可以来自多家供应商,每家供应商又销售多种产品,这就称之为 多对多的关系。
创建关联表
此时,要想确定产品与供应商的唯一关系,必须再创建一个 关联表,专门用来连接产品和供应商。
products_suppliers 表:
| productID | supplierID |
|---|---|
| 2001 | 501 |
| 2002 | 501 |
| 2003 | 501 |
| 2004 | 502 |
| 2001 | 503 |
其中 productID 与 supplierID 都 外键。
CREATE TABLE products_suppliers (
productID INT UNSIGNED NOT NULL,
supplierID INT UNSIGNED NOT NULL,
PRIMARY KEY (productID, supplierID),
FOREIGN KEY (productID) REFERENCES products (productID),
FOREIGN KEY (supplierID) REFERENCES suppliers (supplierID)
);
INSERT INTO products_suppliers VALUES (2001, 501), (2002, 501),
(2003, 501), (2004, 502), (2001, 503);
移除旧的外键
从 products 表中移除 supplierID 字段,它是在一对多的关系中做外键使用的,但有了关联表,它就没用了。移除之前,需要先 移除 针对该字段的 外键,此时需要知道该键的 约束名称,这是由系统生成的。可以使用 SHOW CREATE TABLE procuts 来查看。
查看外键的约束名称
SHOW CREATE TABLE products \G
Create Table: CREATE TABLE `products` (
`productID` int(10) unsigned NOT NULL AUTO_INCREMENT,
`productCode` char(3) NOT NULL DEFAULT '',
`name` varchar(30) NOT NULL DEFAULT '',
`quantity` int(10) unsigned NOT NULL DEFAULT '0',
`price` decimal(7,2) NOT NULL DEFAULT '99999.99',
`supplierID` int(10) unsigned NOT NULL DEFAULT '501',
PRIMARY KEY (`productID`),
KEY `supplierID` (`supplierID`),
CONSTRAINT `products_ibfk_1` FOREIGN KEY (`supplierID`)
^^^^^^^^^^^^^^^
REFERENCES `suppliers` (`supplierID`)
) ENGINE=InnoDB AUTO_INCREMENT=1006 DEFAULT CHARSET=latin1
删除外键
然后就可以用其约束名称来删除外键了:
ALTER TABLE products DROP FOREIGN KEY products_ibfk_1;
SHOW CREATE TABLE products \G
删除之后,用 SHOW CREATE TABLE 查看就看不到 CONSTRAINT 了。
删除字段
最后,可以删除该字段了:
ALTER TABLE products DROP supplierID;
DESCRIBE products;
多表查询
使用 SELECT ... JOIN 进行多表查询。
SELECT P.name AS `Product Name`, price, S.name AS `Supplier Name`
FROM products_suppliers AS `PS`
JOIN products AS `P` ON PS.productID = P.productID
JOIN suppliers AS `S` ON PS.supplierID = S.supplierID
WHERE price < 0.6;
+--------------+-------+---------------+
| Product Name | price | Supplier Name |
+--------------+-------+---------------+
| Pencil 3B | 0.52 | ABC Traders |
| Pencil 3B | 0.52 | QQ Corp |
| Pencil 6B | 0.47 | XYZ Company |
+--------------+-------+---------------+
一对一关系
假设有些产品有一些可选项,如照片、说明等。与其将这些信息保存到 products 表中,不如将其单独保存,这样更有效率。我们为其创建一个新表 product_details,然后用一对一的关系,将其链接到 products 表中。
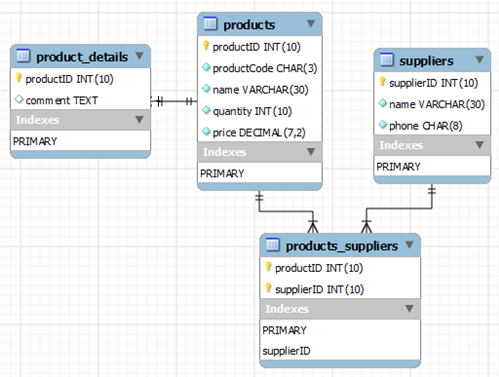
CREATE TABLE product_details (
productID INT UNSIGNED NOT NULL,
comment TEXT NULL,
PRIMARY KEY (productID),
FOREIGN KEY (productID) REFERENCES products (productID)
);
DESCRIBE product_details;
+-----------+------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+------------------+------+-----+---------+-------+
| productID | int(10) unsigned | NO | PRI | NULL | |
| comment | text | YES | | NULL | |
+-----------+------------------+------+-----+---------+-------+
附表
用户权限列表
访问级别
即 Privilege Level。
**.*db_name.*db_name.tbl_nametbl_namedb_name.routine_name
可授予、可撤消的静态权限
| 权限 | 授权的操作 | 访问级别 |
|---|---|---|
| ALL [PRIVILEGES] | 所有权限,但不包括 GRANT OPTION 与 PROXY | 特定级别 |
| ALTER | ALTER TABLE |
全局,库,表 |
| ALTER ROUTINE | 修改、删除存储例程 | 全局,库,例程 |
| CREATE | 创建库和表 | 全局,库,表 |
| CREATE ROUTINE | 创建存储例程 | 全局,库 |
| CREATE TABLESPACE | 创建、修改、删除表空间及日志文件组 | 全局 |
| CREATE TEMPORARY TABLES | CREATE TEMPORARY TABLE |
全局,库 |
| CREATE USER | CREATE USER,DROP USER,RENAME USER,REVOKE ALL PRIVILEGES |
全局 |
| CREATE VIEW | 创建、修改视图 | 全局,库,表 |
| DELETE | DELETE |
全局,库,表 |
| DROP | 删除库、表、视图 | 全局,库,表 |
| EVENT | 使用事件,用于事件调度 | 全局,库 |
| EXECUTE | 执行存储例程 | 全局,库,例程 |
| FILE | 用户可以让服务端读写文件 | 全局 |
| GRANT OPTION | 为他人授予、撤消权限 | 全局,库,表,例程,代理 |
| INDEX | 创建、删除索引 | 全局,库,表 |
| INSERT | INSERT |
全局,库,表,字段 |
| LOCK TABLES | LOCK TABLES,需有 SELECT 权限 |
全局,库 |
| PROCESS | SHOW PROCESSLIST |
全局 |
| PROXY | 用户代理 | 用户之间 |
| REFERENCES | 创建外键 | 全局,库,表,字段 |
| RELOAD | FLUSH 操作 |
全局 |
| REPLICATION CLIENT | 用户可以查询哪些是主、从服务器 | 全局 |
| REPLICATION SLAVE | 从服务器读取主服务器的 binlog | 全局 |
| SELECT | SELECT |
全局,库,表,字段 |
| SHOW DATABASES | SHOW DATABASES |
全局 |
| SHOW VIEW | SHOW CREATE VIEW |
全局,库,表 |
| SHUTDOWN | mysqladmin shutdown |
全局 |
| SUPER | 其它管理操作,如 CHANGE MASTER TO,KILL,PURGE BINARY LOGS,SET GLOBAL,mysqladmin |
全局 |
| TRIGGER | 触发器操作 | 全局,库,表 |
| UPDATE | UPDATE | 全局,库,表,字段 |
| USAGE | 无权限 |
可授予、可撤消的动态权限
| 权限 | 说明 | 访问级别 |
|---|---|---|
| AUDIT_ADMIN | 配置审计日志 | 全局 |
| BINLOG_ADMIN | 控制二进制日志 | 全局 |
| CONNECTION_ADMIN | 控制连接限制 | 全局 |
| ENCRYPTION_KEY_ADMIN | InnoDB 密钥轮换 | 全局 |
| FIREWALL_ADMIN | 管理所有用户的防火墙规则 | 全局 |
| FIREWALL_USER | 管理自己的防火墙规则 | 全局 |
| GROUP_REPLICATION_ADMIN | 控制组复制 | 全局 |
| REPLICATION_SLAVE_ADMIN | 控制普通复制 | 全局 |
| ROLE_ADMIN | WITH ADMIN OPTION |
全局 |
| SET_USER_ID | 为其他用户设置 DEFINER 值 |
全局 |
| SYSTEM_VARIABLES_ADMIN | 修改或保持全局系统变量 | 全局 |
| VERSION_TOKEN_ADMIN | Enable use of Version Tokens UDFs. | 全局 |