
深入了解复制
基于语句的复制
MySQL 5.0 及较早版本只支持逻辑复制。
在主服务器上,把导致数据变化的 查询 保存到日志中。
优点
部署简单
本地保存日志,异地重演,即完成同步。
日志事件比较简洁
相对来说,不会占用太多带宽。
便于检查
日志文件可以查到造成数据更改的所有语句,可用于审计。
逻辑复制中,重演的过程大体上是普通的 SQL 操作,所有修改是以一个容易理解的机制发生的,更便于检查和判断当下发生了什么。
在操作上有更大的灵活性
当主从服务器的 数据格局有差异 时,逻辑复制更加适用。
例如,主从 服务器上的表格有差异,但数据类型是兼容的,或者字段的顺序也有所差异等等。逻辑复制使得在从服务器上对数据格局的修改更加容易,减少当机时间。
缺点
某些语句无法复制
在实际使用中,逻辑复制并没有看起来那么简单。除了查询文本之外,主服务器上的许多变化还决定于其它因素。例如,这些语句在主服务器和从服务器上可能执行的次数会不同,结果就是,MySQL 二进制日志的格式中除了查询文本之外,还会包括几位元数据,如当前的时间戳。即便如此,仍然有 一些语句是 MySQL 无法正确复制的,比如使用 CURRENT_USER() 函数的查询,以及预储程序和触发器。
底线:如果要使用 触发器 或 预储程序,就不要使用逻辑复制。
修改必须是线性的
逻辑复制要求对数据的修改必须是线性的,即序列化的。这就会 需要更多的锁定,有时简直是太多了。不是所有的存储引擎都能与逻辑复制配合使用的。
基于行的复制
从 MySQL 5.1 开始支持行复制,在二进制日志中记录数据的真实修改,更像大多数其它数据库产品的复制手段。
优点
更加安全
所有的修改都能正确复制,更加安全。
有些修改还可以复制的更加高效,因为从服务器 不必重演 在主服务器上引起行变化的那个 查询。
很少有行复制不能胜任的情况,所有的 SQL 结构、触发器、预储程序等,它都能正确处理。只有在进行一些很智能化的操作时才会有些局促,如修改数据格局。
更高的并发
主从服务器上只需要 很少的锁定,因此有更高的并发。行复制不需要特别强的序列化就可以完成重演。
日志记录更加直接
行复制在日志中所记录的是 发生变化的数据本身,因此二进制日志中的记录就是在主服务器上真实发生的变化内容。不需要根据语句来猜测它修改了什么数据。因此,用行复制能够 更加了解哪些数据发生了变化,对数据的修改也记录的更好。
可以记录历史数据
在某些情况下,行复制的二进制日志还会记录 历史数据,对于数据的恢复特别有帮助。
对 CPU 的需求不大
在很多情况下,行复制对 CPU 的需求不大,因为它不需要像逻辑复制那样计划和执行查询。
有助于解决数据不一致
在某些情况下,行复制有助于更快地查找并解决数据不一致的问题。
例如,如果在主服务器上更新了一行,但从服务器上根本就没有这一行,此时逻辑复制不会失败,而行复制就会 报错并停止。更早发现,更早解决。
范例
对查询的重演有时会引起很大的开销。例如,以下这个查询是从一个巨大的表中读取一些统计信息,保存到一个小表里:
mysql> INSERT INTO summary_table(col1, col2, sum_col3)
-> SELECT col1, col2, sum(col3)
-> FROM enormous_table
-> GROUP BY col1, col2;
假设在 enormous_table 表中,col1 和 col2 的组合只有三种,该查询会扫描源表中的许多行,而在目标表中保存的结果却只有三行。把该事件做为语句复制会使从服务器重复所有这些操作,而目的只是为了生成三行数据,而如果使用行复制就要简单的多了,更加高效。
😈 从上例可以看出,是哪些语句使用行复制才会更加高效呢?当然是从数据修改的结果出发来看了,只要是使用语句大张旗鼓地进行查询,得到的结果却只是对少数的几行数据进行修改,此时用行复制就更高效。
缺点
因为日志事件中不包含语句,因此 很难了解执行了哪些 SQL 语句,有时候这很重要。
复制来的变化在从服务器中应用时,是以完全不同的方式进行的,它执行的根本不是 SQL 语句。事实上,行复制应用修改的过程是在 黑箱 中进行的,谁都看不到服务器做了什么,这方面的文档也不够详细。
在使用多级从服务器时,如果它们使用相同的配置的行复制。假设在会话级变量 binlog_format 为 STATEMENT 的情况下,执行了一条语句,会在发起该语句的服务器上,以语句的形式记录在日志中。但是,第一级从服务器会把该事件以行复制的格式中继下来,传递给复制链上的其它从服务器。这样,用户本来希望在日志中以语句的格式记录,可是该事件穿越复制拓扑时,还是被 强行切换 成了行复制。
有些操作,逻辑复制应付的来,但行复制不行,比如在从服务器上修改数据格局。
哪种复制方法更好?
因为每种复制的方法都有最适合自己的具体情况,MySQL 可以在逻辑复制和行复制这两种方法之间 动态切换。
默认是使用逻辑复制,当发现某个事件无法用语句正确复制时,它会切换成行复制。
当然,在需要时,也可以手动控制使用哪种方法,通过配置会话变量 binlog_format 来实现。
理论上,行复制可能整体来说更好一些,而且在实际生产中对于大多数人来说工作的比较好。
复制会用到的文件
除了二进制日志和中继日志,还有一些文件是在复制过程中会用到的。MySQL 会根据当前的配置来处理这些文件。不同版本的 MySQL,放置这些文件的默认位置可能所有不同。
mysql-bin.index 二进制日志文件索引
启用了二进制日志以后,服务器中还会存在与其同名的文件,但加了 .index 后缀。该文件会跟踪磁盘中的二进制日志。它与表格索引不同,文件中的每一行包含了一个二进制日志文件名。
MySQL 依赖这个索引文件来定位二进制日志,所以不要手动干预它。
$ sudo cat /var/log/mysqld/mysql-bin.index
/var/log/mysqld/mysql-bin.000001
/var/log/mysqld/mysql-bin.000002
/var/log/mysqld/mysql-bin.000003
/var/log/mysqld/mysql-bin.000004
/var/log/mysqld/mysql-bin.000005
mysql-relay-bin.index 中继日志索引
MySQL 依赖这个索引文件来定位中继日志。
$ sudo cat /var/log/mysql/mysql-relay-bin.index
/var/log/mysql/mysql-relay-bin.000005
master.info
该文件保存的是 主服务器的详细信息,从服务器根据该文件中的信息来连接到主服务器。MySQL 依赖它来连接主服务器。
该文件中包含从服务器用户的密码,是明文保存的,因此有必要对权限加以限制。
此处说明一下,本人在使用 MySQL 8.0 测试时发现,该版本已经不再使用该文件来保存主的信息,转而使用数据库,具体为 mysql.slave_master_info 表格,这个改进还是很有必要的。详见官方文档。
relay-log.info
该文件包含了从服务器中在二进制日志和中继日志中的 坐标。MySQL 依赖它来了解记起之前复制到什么位置。
同样,该文件在 MySQL 8.0 中也转而使用数据库代替了,具体为 mysql.slave_relay_log_info 表格。
用这些文件来记录复制和日志的状态,这是一个比较粗糙的办法。而且不幸的是,它们还不是同步写入的,所以如果赶上服务器突然断电,这些文件还没有被刷新到磁盘中,服务器重启时,这些文件的内容可能就不是正确的。在 MySQL 5.5 之后已经有所改进,即前面提到的对
sync_*的配置。
.index文件会与另一个配置交互,即expire_logs_days,该参数用于定义 MySQL 应该如何删除过期的二进制日志。如果mysql-bin.index文件中所指定的文件在磁盘上不存在,自动删除在某些版本的 MySQL 中就会不管用。事实上,即使用PURGE MASTER LOGS语句都无法删除。解决办法通常是用 MySQL 服务器来管理二进制日志。总之不要手动rm删除这些文件,以免影响它们的正常运行。要想实现自动删除日志,必须显式指定删除策略。可以使用
expire_logs_days或其它办法,同时要有针对性地设置备份策略。
把复制事件发送给其它从服务器
启用 log_slave_updates 选项,可以使当前的从服务器成为其它从服务器的主服务器。SQL 线程执行的那些事件会被写入从服务器自己的二进制日志中,然后它自己的从服务器再来读取。
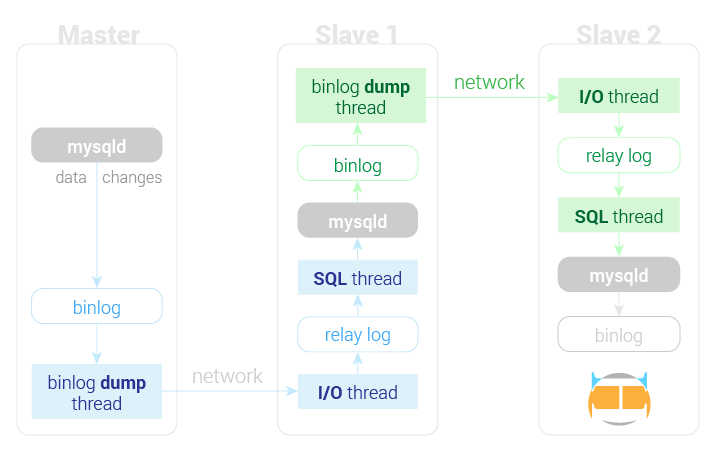
启用 log_slave_updates
因为启用了 log_slave_updates,slave1 在重演事件后,会将其写入自己的二进制日志,slave2 就可以把 slave1 的事件放到自己的中继日志,然后执行。于是,master 中发生的改变会一路传播到 slave2。因此,通常建议默认就开启 log_salve_updates 选项,这样,在需要创建下一级从服务器时,可以直接连接,无需重启。
同一事件的日志坐标在各服务器上是不同的
slave1 写入自己的二进制日志时,同一个事件在日志中所处的位置与 master 中它所处的位置一定是不同的。因此:
即使两个服务器其复制是处于相同的 逻辑点 上,也无法保证它们处于相同的 日志坐标。
这一点让某些任务处理起来特别复杂,比如让一个从指向新的 主,或把从改为 主。
唯一的 Server ID 很重要
如果不为服务器仔细分配唯一的 server ID,这样配置就容易出现细微的错误,甚至会导致复制失败。
唯一的 server ID 有助于防止复制陷入 死循环。SQL 线程在读取中继日志时,会忽略掉 Server ID 为自己的事件,就是通过该行为来防止死循环的。
复制的过滤器
使用复制过滤器可以实现只复制服务器的 部分数据,实际上不是什么好事。使用复制过滤器经常会产生一些问题。
有两类复制过滤器:针对二进制日志的过滤器,以及针对中继日志的过滤器。
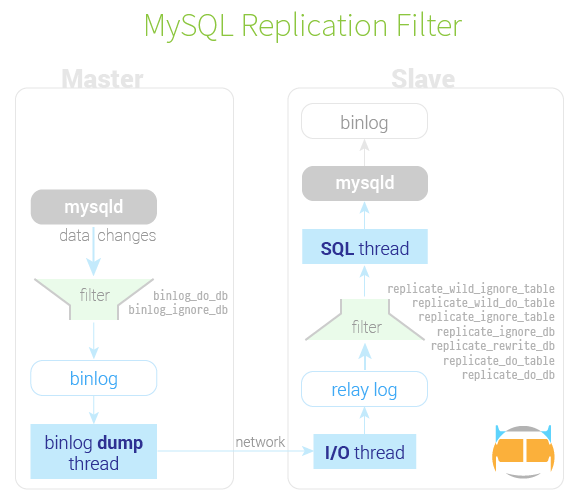
在从服务器中启用 replicate_* 这些选项以后,当 SQL 线程从中继日志中读取事件时,会针对事件进行过滤,可以 复制 或 忽略 一个、多个数据库,把一个数据库重写成另一个,基于 LIKE 模板的匹配来复制或忽略特定的表格。
不要轻易使用过滤器
无论在主服务器还是从服务器上,*_do_db 和 *_ignore_db 这两类选项工作起来并不总能如人愿。它们并不是针对数据库名称进行过滤,而是针对 当前默认的数据库 进行过滤。
如果在主服务器上执行以下语句:
mysql> USE test;
mysql> DELETE FROM sakila.film;
因为当前使用的数据库是 test,*_do_db 和 *_ignore_db 参数只会针对数据库 test 进行过滤,而不会过滤其它数据库的语句,所以第二条的 DELETE 语句就不会被过滤,因为它是针对数据库 sakila 的。*_do_db 和 *_ignore_db 参数虽然有用,但是比较有限,而且使用的比较少,必须特别谨慎地使用。稍有错误,就很容易导致复制发生同步错误或失败。
不仅如此,使用了这些参数以后,就无法实现 “从备份中进行针对特定时间点的数据恢复” 了。对于绝大多数情况,都不应该使用。
复制通道
Replication Channels
从 MySQL 5.7.6 开始,引入了复制通道的概念。
复制通道用来表示由主流动到从的事务的路径。
为了兼容旧版本,MySQL Server 在启动时会自动创建一个 默认通道,名称为空字符串 ""。该通道会始终存在,它无法被用户创建或破坏。如果没有其他的非空名称的通道被创建,复制语句会只在默认通道上进行,以保证低版本的从中的复制语句能正常执行。
通道独立工作
复制通道中包含了由主到从的事务的路径,在多源复制中,一个从会打开多个通道,每个主用一个,每个通道都有其 自己的中继日志和 SQL 线程。
复制通道的 I/O 线程接收到事务以后,将其加入通道的中继日志,并交给 I/O 线程。这样,通道就可以独立工作了。
- 一个复制通道与一个主机名和端口号相关联。
- 可以给同一组主机名/端口号的组合分配多个通道。
- 在 MySQL 5.7 的多源复制中,可以为一个从增加的通道的最大数量为 256 个。
- 每个复制通道必须拥有一个唯一的、非空的名称。
- 每个通道可以被单独配置。
复制的拓扑
组建复制拓扑期间的基本准则:
- 一个 MySQL 复制实例只能有一个 主
- 每个从必须有一个唯一的 Server ID
- 一个主可以有多个从服务器
- 一个从可以把主的修改传播下去,自己可以做为其它从的 主
一主多从
一主多从的拓扑中,每个从只和主进行通信。
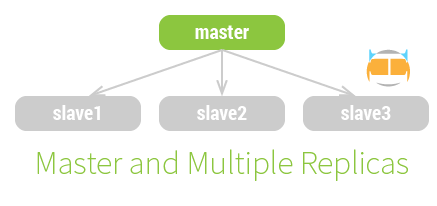
该拓扑适合 写少读多 的情况。可以把读取的压力分散到任意数量的从服务器上,直到数量多到从服务器产生的 负载 太大,或占用了过多的 带宽 为止。可以一次性配置多个从服务器,也可以需要时再加。
用途
虽然这个拓扑很简单,但它的灵活性已经满足许多需求了:
- 把不同的从用作 不同的角色:如,增加不同的索引或使用不同的存储引擎
- 把其中的一个从配置成为 候补主服务器,只允许走复制流量
- 把其中的一个从放到远程数据中心,用于 灾难恢复
- 延迟复制一或多个从,用于灾难恢复
- 把其中的一个从用于备份、培训、开发、平台
特点
该拓扑使用简单,拿二进制日志的位置来横向比较各个从服务器,这一点非常方便。因为它们都是一样的。
如果把所有的从服务器在相同的逻辑复制点停掉,会发现它们都在读取主日志的同一个物理位置,这是一个非常好的特性,简化了许多管理任务,比如把从提升为 主。
该特性只存在于这些兄弟从服务器之间,即同一级别的 从。
静态主主
两个服务器,每个都配置成既是 主,又是 从,互为主从,同时都可以写入。
两个服务器不分主次,每个都是主动做另一个的主服务器,同时还是另一个的从服务器。
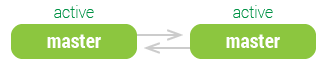
这种互为 主从 的拓扑只有在非常特殊的情况下才会使用,比如地理位置比较远的两个办公室,每个办公室都需要在本地有一个数据的可写副本。
缺点
该拓扑最大的问题是 如何管理相互冲突的修改。
例如,两端的服务器可能会尝试 同时修改同一行的数据,或者,两个服务器同时向某个表格中插入一个 AUTO_INCREMENT 字段。
两个服务器上 以不同顺序发生的更新 也会迫使数据无法同步。
如果复制因为错误而停止了,但某些程序却仍然向这两个服务器写入数据,两端数据的差异会越来越大,产生的差异几乎是无法同步的。
动态主主
静态主主的问题这么多,两个服务器都想当老大。于是产生了一个变体:
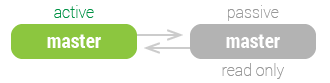
与静态主主的区别在于,同一时刻,一个是主动,一个是被动。
所谓被动,就是指该服务器在当前状态是 只读 的。
使用该配置,主动和被动服务器可以很轻松地互换,因为它们的配置是对称的,这让失效切换和自动恢复变得更容易。无需离线就可以进行维护、优化表格、升级操作系统、升级应用程序、升级硬件。
工作原理
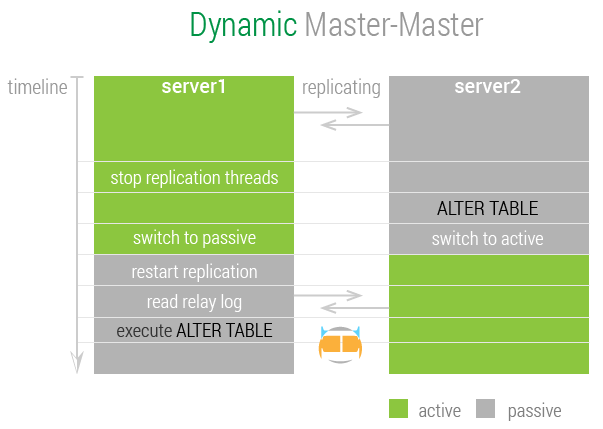
以执行 ALTER TABLE 为例,说明该拓扑工作原理。
因为服务器在运行 ALTER TABLE 语句时,会锁定整个的表格,禁止对其读取和写入,这个过程有可能持续较长时间,会影响其它服务。但在该拓扑中,只在被动服务器上 运行该语句,可以保证不影响其它服务的运行,同时也不受其它因素的影响。
- 处于主动模式的 server1 停止自身的复制线程,以保证自己不会复制、处理 server2 的更新
- 处于被动模式的 server2 开始执行
ALTER TABLE语句 - 二者互换角色
- 处于被动模式的 server1 恢复复制线程,server1从server2 中复制其更新
- server1 读取本地中继日志,执行同样的
ALTER TABLE语句
利用这种拓扑可以避免很多问题,也可以规避一些 MySQL 的限制。
配置方法
在双方服务器上都执行以下步骤,以便得到对称的配置:
- 确保双方拥有相同的数据
- 启用二进制日志,选择唯一的 Server ID,增加复制帐户
- 启用复制更新的日志
- 配置被动服务器为只读,以防止产生与主动服务器冲突的修改
- 启动每个服务器的 MySQL 实例
- 把每个服务器都配置为对方的 从,从新建的二进制日志开始
复制的流程
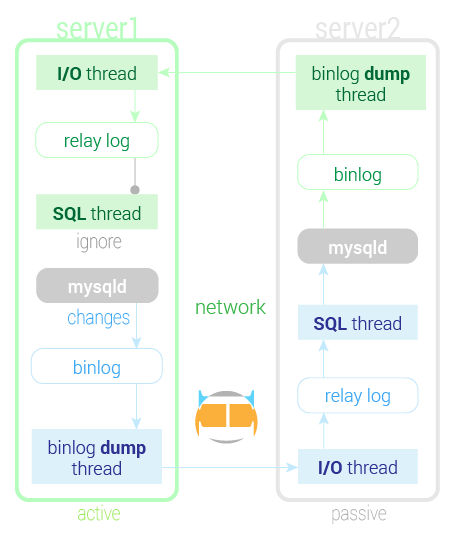
当主动模式的 server1 从 server2 的二进制日志中读取到自己的事件时,会忽略,因为事件的 Server ID 是它自己。
使用这种拓扑有点像创建了一个热备,只不过还可以用这个热备来提升性能。可以用来读取查询、备份、离线维护、升级等等,这些事在真的热备上却是无法完成的。但是该拓扑没有带来更好的写入性能。 这是一个非常重要、非常常用的复制拓扑。
带从的主主
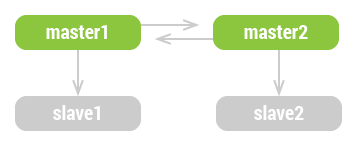
该拓扑的优势是额外的冗余,在每一侧都消除了单点失效。同时,也可以用从缓解读取压力。
可用于本地失效切换,主 失效时可以把从提升为 主,只是做起来有些复杂。
环状复制
双主的配置实际上只是环状复制的一个特殊案例。环状拓扑可以有三个或多个主服务器,每个都是它前面的 从,它后面的 主。环状拓扑也称圆形复制。
这种拓扑没有主主的那些关键优势,比如对称配置以及便捷的失效切换。复制特别依赖于拓扑中的每个节点一直可用,大大增加了整个系统失效的风险。如果从中拿掉一个,从该节点产生的所有复制事件就会进入一个死循环:这些事件会在剩下的复制链中永远循环下去,因为能够过滤掉该事件的只有它自己。
通常来说,环状复制是很脆弱的,应该避免使用。
主 - 分主 - 从
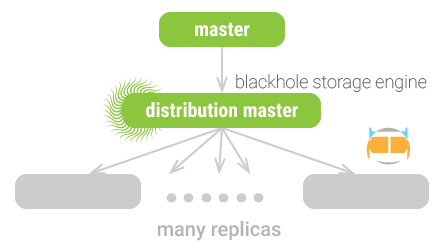
当从服务器足够多的时候,它们会给主服务器带来很大的负载,每个从服务器都会在主服务器上创建一个新的线程,用它来执行 binlog dump 命令。该命令会从二进制日志中读取数据,将其发送给从服务器。这个操作需要为每个从服务器都重复进行,它们并不会共享所需的资源。
如果有许多从服务器,产生了一个特别巨大的二进制日志事件,如 LOAD DATA INFILE 这样的语句,主服务器的负载会急剧增加。主服务器甚至可能耗尽内存以致崩溃,因为所有从服务器同时在请求同一个巨大的事件。另一方面,如果从服务器全都请求不同的事件,而且这些事件都已经不在缓存中了,这会引起大量的磁盘寻道操作,同样会干扰主服务器的性能,产生互斥连接。
基于这个原因,如果确实需要大量从服务器,最好把主服务器的负载分摊给分主服务器,即 distribution master,下文简称分主。分主本身也是一个从服务器,它唯一的目的就是读取主服务器的二进制日志,然后提供给其它从服务器读取。相当于在主与从之间做了个缓冲区。可以把所有的从服务器连接到分主上,由分主来隔离负载。为了避免分主真的执行那么多的查询操作,可以把它的表格改为 黑洞存储引擎。
很难说一个主服务器管理超过多少从服务器才需要一个分主,粗略地推算,如果一个主服务器接近满负荷运转时,它下面不建议超过 10 个从服务器。如果写入操作特别少,或者只需要复制表格的一小片断,主服务器也许可以管理更多的从服务器。
另外,不一定限制只使用一个分主,需要时可以用多个。有时候,配置 salve_compressed_protocol 有助于在主服务器上节省一部分带宽,这一点对跨数据中心的复制尤其有用。
分主还要以用于其它目的,比如应用过滤器,向二进制日志事件中重写规则。这样做比从服务器上传统的重演、重写、过滤更高效。
如果在分主上使用黑洞表格,会比平时能承担更多的从服务器。虽然 分主 会执行查询,但这些查询的开销会非常小,因为黑洞表格不会含有任何数据。
缺点
这种方法存在一些 BUG,比如在某些情况下会忘记向其二进制日志中添加自增的 ID,所以使用时要特别小心。
如何确保分主中的所有表格都使用黑洞存储引擎,这是一个问题。
如果有人在主服务器上创建了一个新表格,使用的是其它存储引擎,虽然可以通过指定其 storage_engine 选项来解决:
storage_engine=blackhole
但该选项只会影响那些没有显式指定存储引擎的 CREATE TABLE 语句。如果现有的程序是无法控制的,该拓扑就会变得脆弱。
另外,要想用从服务器之一来替换主服务器是非常困难的,因为分主始终认为,所有的从服务器其二进制日志坐标与主服务器应该始终不同。
树状拓扑
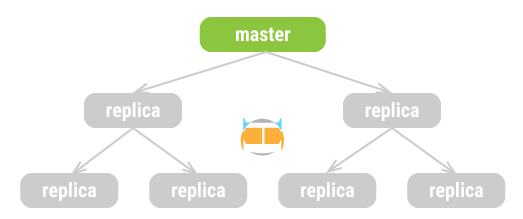
树状拓扑适合远距离同步数据,或用于提升读取能力,这种拓扑更容易管理。
优点
树状拓扑缓解了主服务器的负载
缺点
中间层的任何失效都会影响到多个服务器,中间层越多,处理失效就越复杂、越困难。
自定义拓扑
MySQL 的复制是非常灵活的,完全可以按照自己的需求来单独设置一个解决方案。通常需要把过滤器、分布式、复制的组合应用到不同的存储引擎。还可以用一些特殊的处理,比如前面提到的使用黑洞存储引擎。可以设计的特别精密,最大的限制只是你是否有能力做好监控和管理,以及网络带宽、CPU 等资源是否足够。
分散复制
为了充分利用本地读取的高效,并且能尽可能地把要处理的数据放在内存中快速读取,每次可以只复制 少量 的数据给从。
如果每个从上都有一小块主的数据,在需要时直接读取这些从,可以充分地利用它们的内存,明显提升读取的性能。每个从也可以为主分担一小块写入的压力,这样一来,提升主的写入能力的同时,还不会拖累从。
与其它方法相比,这种拓扑的好处是,主服务器依然保存着 所有 数据。这意味着:
- 一个写入查询所需的数据,在一个服务器上一次都能获取,无需在多个服务器上查找。
- 对于读取的查询,如果每个从上都没有该查询所需的完整数据,还可以读取主。
即使从无法分担全部的读取压力,它们毕竟还是可以分担许多的。
以数据库为单位 分散复制
最简单的办法是,在主服务器上,把数据分区存放在不同的数据库中,然后把每个数据库分别复制到不同的从。
例如,把公司不同部门的数据分别存放到不同的从,每个从都应该使用 replicate_wild_do_table 选项把复制限制在特定的表格上:
replicate_wild_do_table = sales.%
使用分主
可以用分主对要复制的数据进行过滤。
例如,想要从负载严重的服务器上仅仅复制一部分数据,然后穿越一个缓慢或昂贵的网络,可以在本地设立一个分主,上面使用黑洞和过滤规则。借助过滤规则,分主可以从其日志中去掉无用的条目,一方面有助于去掉主中危险的日志设置,另一方面还不需要把整个日志扔到网上,传输给远处的从。
拆分功能
OLTP:online transaction processing,在线事务处理
OLAP:online analytical processing,在线分析处理
许多应用程序同时包含了这两种处理的查询。
- OLTP 查询通常很短,是事务性的,
- OLAP 查询通常较大、很慢,不需要最新的数据
这两类查询带给服务器的压力也是完全不同的,因此,只有在不同的配置、不同的存储引擎、不同的硬件中,它们才能各自发挥最好的性能。
对此,常用的办法是把 OLTP 服务器中的数据,复制到一个专门为 OLAP 负载设计的从中。这些从可以拥有不同的硬件、配置、索引、存储引擎。如果你肯把一个从专门用于 OLAP 查询,你就一定愿意忍受更多的复制间隔,否则会导致该从的服务质量的下降。带来的好处是,有些任务如果在非专门从上进行会导致不可接受的性能降低,而在专用的上面就可以完成,例如需要很长时间来运行的查询。
虽然不需要针对复制进行特殊的配置,不过如果确实节省很多资源,你可以选择从主滤掉一些,从 就不用再保存这些数据了。在中继日志上,即使过滤掉一小部分数据,也会有助于减少 I/O 和缓存的活动。
数据归档
可以在从中将数据归档,即该数据保存在从中,但会从主中删除。
在主上运行删除查询,并确保这些查询不会在从上执行。
通常有两种办法:
在主服务器上选择性地禁用二进制日志
这种方法需要运行一个专用来清除主服务器数据的进程,先在进程中执行 SET SQL_LOG_BIN=0,然后清除数据。
优点:从上不需要特殊配置,而且,因为语句没有保存到二进制日志中,执行起来更有效率。
缺点:无法使用 主 上的二进制日志进行审计了,也无法用来进行时间点恢复了,因为日志中不再包含这些修改。同时还需要 SUPER 权限。
在从服务器上使用 replicate_ignore_db 过滤规则
这种方法是在主上执行清除数据语句前,先 USE 特定的数据库。
例如,可以在主上先创建一个名为 purge 的数据库,然后在从上的 my.cnf 配置文件中使用 replicate_ignore_db=purge,重启服务器。从就会忽略 USE 该数据库的语句。
缺点:从会取回一些它不需要的日志事件。有潜在的风险:某些人可能会不小心在 purge 数据库上执行了非清除的查询,这些本该复制的事件却不会被 从 复制。
只读从服务器
许多企业愿意把从服务器配置成只读,这样的话,复制不会被无意的修改破坏掉。可以用 read_only 配置变量来实现,它会把大多数写入操作禁用:除了复制进程、拥有 SUPER 权限的用户以及临时表格。
创建一个日志服务器
通过复制可以创建一个日志服务器,其中不保存数据,其唯一目的是为了便于重演、过滤指定的二进制日志事件。这样做非常有利于在崩溃后重启复制,也有助于时间点恢复。
想像一下,你有一组二进制日志或中继日志,也许来自备份,也许来自一个崩溃的服务器,现在你希望能重演其中的事件。可以用 mysqlbinlog 来提取事件,但更方便快捷的方法是:配置一个没有任何数据的 MySQL 实例,并让它认为这些二进制日志是它自己的。之所以不需要任何数据,是因为它并不需要执行这些日志,只需要 把日志提供给别的服务器。因此它需要一个复制帐户。
如果只是倒计时需要创建一个日志服务器,可以使用 MySQL Sandbox 脚本。
实施流程
假设现有的日志名为 somelog-bin.000001,somelog-bin.000002 等待,把它们放到日志服务器的二进制日志目录,假设为 /var/log/mysql,然后 编辑 my.cnf:
log_bin = /var/log/mysql/somelog-bin
log_bin_index = /var/log/mysql/somelog-bin.index
服务器不会自动发现这些日志文件,因此必须 手动更新日志索引文件:
# ls -l /var/log/mysql/somlog-bin.[0-9]* > /var/log/mysql/somelog-bin.index
要确保用来运行 MySQL 的 Linux 用户有权读写日志索引文件。
启动日志服务器,并运行 SHOW MASTER LOGS 以确认它识别出了这些日志文件。
使用日志服务器的优势
对于数据恢复来说,使用日志服务器比 mysqlbinlog 要更好:
- 复制本身是应用二进制日志的一种成熟可靠的手段,经过了无数用户的测试。而
mysqlbinlog不能保证以同样的方式进行工作,还不一定能准确地重现修改。 - 更快,因为它不再需要从日志中抽取语句,然后发送给 mysql。
- 可以轻易地查看进度
- 可以忽略无法复制的语句,更容易对付错误
- 可以便捷地过滤复制事件
- 有时
mysqlbinlog可能无法读取二进制日志,因为日志格式发生了变化。