
grep 、sed、awk 被称为 linux 中的 “三剑客”。
- grep 适合单纯的 查找 或 匹配 文本
- sed 适合 编辑 匹配到的文本
- awk 适合 格式化 文本,对文本进行较复杂格式处理
GREP
语法
检索文件内容,列出模板所在的行。模板可以是字符串或正则表达式,支持 BRE 和 ERE。
grep [-A] [-B] [--color=auto] '模板' filename
-A 列出该行及其后 n 行
-B 列出该行及其前 n 行
--color=auto 标记颜色
-n 显示行号
范例
正向匹配
$ last | grep 'root'
反向匹配
$ last | grep -v 'root'
使用高亮
grep --color=auto 'MANPATH' /etc/man_db.conf
统计匹配次数
$ last | grep -c root
10
忽略大小写
$ grep -i shit file
显示行号
$ grep -n shit file
以文本方式对待二进制文件
$ grep -a shit bin
查看关键字所在行的前后内容
$ dmesg | grep -n -A1 -B5 --color=auto 'qxl' file
A: After。-A1 关键字所在行的后 1 行。
B: Before。-B5 关键字所在行的前 5 行。
SED
Stream EDitor
sed 是一种流编辑器,它是文本处理中非常强大的工具,能够完美的配合正则表达式使用,功能不同凡响。
处理时,把当前处理的行存储在临时缓冲区中,称为 “模板空间”(pattern space),接着用 sed 命令处理缓冲区中的内容,处理完成后,把缓冲区的内容发送到屏幕。接着处理下一行,这样不断重复,直到文件末尾。它不会主动修改文件内容。
Sed 主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
语法
sed [options] ‘command’ file(s) sed [options] -f scriptfile file(s)
[ options ]
-e script 在命令行用指定的参数来处理,常用于同时进行 多个操作
-f script 用指定的 脚本 文件来处理
-n 仅显示 由脚本处理过的行,否则会显示文件所有行
-r 使用 ERE
-i 直接修改文件内容
[ command ]
[n1[,n2]]function
n1, n2:可选,表示选择范围的起止行数
function:
a 在当前行下面插入一行
c 修改指定行的内容
d 删除指定行
i 在当前行上面插入一行
p 输出
s 替换,可以直接进行替换,可搭配正则表达式
sed 后面如果要接超过两个以上的操作时,每个操作之前均要加 -e 。
范例
删除
删除单行
$ cat /etc/passwd | sed '4d'
删除连续多行
$ nl /etc/passwd | sed '2,5d'
删除第 3 行至末行
$ nl /etc/passwd | sed '3,$d'
整行替换
sed '行范围c 替换内容' file
行范围:单行用一个数字表示行号;多行用逗号 , 连接两个行号来表示。
紧随的 c 表示将范围内所有行修改为空格后面的字符串。
替换单行
行范围为一个数字:
$ sed '3c holly shit' file
把第 3 行的全部内容替换为 holly shit。
替换连续多行
行范围为逗号连接的两个行号:
$ nl /etc/passwd | sed '2,5c No 2-5 number'
原来的第 2~5 行,会被替换为一行,内容为 No 2-5 number:
字符串替换
sed 's/关键字/替换/g'
在行内替换匹配的字符串。
s 代表搜索,g 表示 global,全局替换。
如果没有 g 则只替换当前行的 第一个 匹配,加上 g 则替换当前行中 所有 匹配。
替换关键字
$ sed 's/good/bad/' file # 每行仅替换第一个匹配
$ sed 's/good/bad/g' file # 每行替换所有匹配
删除文件中的注释行
cat /etc/man_db.conf | grep 'MAN' | sed 's/#.*$//g'
从 ifconfig 文件中查看 IP 地址
$ ifconfig eth0 | grep 'inet ' | sed 's/^.*inet //g' | sed 's/ netmask.*$//g'
| ipconfig 原始信息 | 取出 IP 地址所在行 | 删除 IP 地址前面字符 | 删除后面字符 |
插入行
a 在当前行下面插入
i 在当前行上面插入
在第 2 行下面加入一行
$ nl /etc/passwd | sed '2a drink tea'
在第 2 行上面插入一行
$ nl /etc/passwd | sed '2i drink tea'
在第 2 行下面加入两行
$ nl /etc/passwd | sed '2a Drink tea or ......\
> drink beer ?\
> holly shit'
不同的行需用 转义符 + 回车 分隔,最后一行的行尾加单引号结束。
查看行
查看第 5-7 行:
$ nl /etc/passwd | sed -n '5,7p'
混合使用
删除第 4 行,替换第 6 行
$ cat /etc/passwd | sed -e '4d' -e '6c no six line'
删除第 4 行,替换第 6~10 行
$ cat /etc/passwd | sed -e '4d' -e '6,10c holly shit'
直接修改原文件
使用选项 -i 可以直接修改原文件,慎用。
直接替换文件内容
$ sed -i 's/.$/!/g' test.txt
在最后一行后面加入一行
$ sed -i '$a This is a test' test.txt
$ 表示最后一行
AWK
本节内容特别感谢 朱双印个人日志 !
简介
AWK 是一种解释执行的编程语言。它非常强大,被设计用来专门处理文本数据。
awk 其实是一门编程语言,它支持条件判断、数组、循环等功能。所以,我们也可以把 awk 理解成一个脚本语言解释器。
由 GNU/Linux 发布的 AWK 版本通常被称之为 GNU AWK,由自由软件基金( Free Software Foundation, FSF)负责开发维护的。 目前总共有如下几种不同的 AWK 版本。
- AWK——这个版本是 AWK 最原初的版本,它由 AT&T 实验室开发。
- NAWK ——NAWK(New AWK)是 AWK 的改进增强版本。
- GAWK—— GAWK 即 GNU AWK,所有的 GNU/Linux 发行版都包括 GAWK,且 GAWK 完全兼容 AWK 与 NAWK。
linux 中常用的是 gawk。
部分 AWK 的典型应用场景
AWK 可以做非常多的工作,下面只是其中的一小部分:
- 文本处理
- 生成格式化的文本报告
- 进行算术运算
- 字符串操作 …
工作流程
AWK 执行的流程:读取、执行、重复。
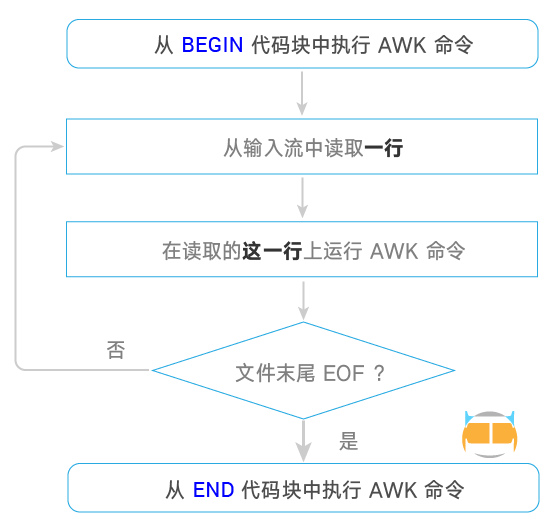
awk 是逐行处理的,默认把 “换行符” 作为一行结束的标记,默认使用空格作为分割符,把每一行切割成若干个字段。分割符可以由用户指定。
每一 行 也叫一个 记录,record。
每一行用分隔符切割之后,剩下的部分叫 字段,filed。
读取
AWK 从输入流(文件、管道或者标准输入)中 读入一行,将其放入内存中。
执行
对于每一行输入,所有的 AWK 命令依次执行。
默认情况下,AWK 命令是针对于每一行输入执行的,但是我们可以将其限制在指定的模式中。
重复
一直重复上述两个过程直到文件结束。
内建变量
awk 的内建变量。
| 变量名称 | 意义 |
|---|---|
| NF | 每行字段的总数 |
| NR | 当前所在的行号 |
| FS | 输入字段之间的分隔符 |
| OFS | 输出字段之间的分隔符 |
| RS | 输入行之间的分隔符 |
| ORS | 输出行之间的分隔符 |
| ARGC | 在命令行提供的参数的个数 |
| ARGV | 存储命令行输入参数的数组 |
| ENVIRON | 与环境变量相关的关联数组变量 |
| FILENAME | 当前文件名 |
| $0 | 整个输入行 |
| $n | 当前输入行的第 n 个字段 |
NR, NF 等内置变量要大写,前面不用加 $ 。
语法
awk [options] 'pattern{action}' filenames
awk [options] '
BEGIN { actions }
/pattern/ { actions }
/pattern/ { actions }
………
END { actions }
' filenames
[options] :选项
pattern :模板
actions :操作
程序的结构
开始块
BEGIN { actions }
BEGIN block,为可选部分。是在程序启动时执行的代码,整个过程中只执行一次。通常用于 初始化变量。
BEGIN 是 AWK 的关键字,必须大写。
主体块
/pattern/ { actions }
Body Block,必选部分。
awk 读取的每一行都会执行一次主体块中的命令。
结束块
END { actions }
END Block,结束块也是可选的。
结束块是在程序结束时执行的代码。END 也是 AWK 的关键字,必须大写。
AWK 内部运转流程
for 每个文件:
for 每一行:
for 每一组 (条件/模板)/操作:
if 存在条件:
if 条件为真
else if 存在模板:
if 匹配模板:
if 存在操作:
执行操作
else:
print 当前行
else (没有模板):
执行操作
选项
可选。
模板
可选。
awk 在逐行处理数据流时,会把模板作为 条件 来进行检查、判断。
如果没有指定模板,文本流中的每一行都会执行对应的操作;如果指定了模板,则只有与模板匹配的、符合条件的行才会执行对应的操作。
模板可以是:
空
模板可以是空的,即可以被省略,此时意味着 每个输入行都满足条件,因此所有行都会被处理。如:
$ awk '{print $0}' file
/正则表达式/
awk 使用 ERE,扩展正则表达式。
正则表达式必须放在一对斜线中间 / /,如果正则表达式中需要使用 斜线,需要 转义。
'/正则表达式/{操作}'
这样的形式是把 匹配 该正则表达式的 行 进行对应的操作。
$ awk '/^adm/{print $0}' /etc/passwd
查找以 adm 开头的行。
'/正则1/,/正则2/{操作}'
这样的形式是指定一个 匹配 的 行的范围。正则1指定起始行,正则2指定结束行,针对从起始行开始一直到结束行的所有行进行操作。
$ awk '/Lee/,/Kevin/{print $0}' file
'(/正则1/)&&(/正则2/){操作}'
如果多个正则表达式需要逻辑运算,可以先用括号包围起来,再使用逻辑运算符。
通过 last 登陆记录统计最近所有用户的登陆次数。
$ last | awk 'BEGIN{print "登陆次数","\t","用户"} \
> ($1 !~ /\(/)&&($1 !~ /reboot/)&&($1 != "") \
> {c[$1]++} END{for(i in c){print c[i],"\t\t",i}}'
登陆次数 用户
66 neo
1 wtmp
5 trinity
10 root
其中的正则表达式 ($1 !~ /\(/)&&($1 !~ /reboot/)&&($1 != "") 是为了排除结果中非用户的行。
{m,n} 重复次数
在使用 {m,n} 来 匹配 前一个字母的 重复次数 时,必须要指定 --posix 和 --re-interval 其中的一个选项。
$ awk --posix '/go{2,5}gle/{print $0}' file
google
goooogle
关系表达式
使用运算符进行操作,可以是字符串或数字的 比较测试。这种模板通过比较测试来定义判断的条件。
awk 支持的关系运算符:
| 关系运算符 | 含义 | 用法示例 |
|---|---|---|
| < | 小于 | x < y |
| <= | 小于等于 | x <= y |
| == | 等于 | x == y |
| != | 不等于 | x != y |
| >= | 大于等于 | x >= y |
| > | 大于 | x > y |
| ~ | 与对应的正则匹配则为真 | x ~ /正则/ |
| !~ | 与对应的正则不匹配则为真 | x !~ /正则/ |
定位每行字段数等于 5 的行,查看第 4 个字段:
$ awk 'NF==5 {print $4}' file
查看第 3 行到第 6 行的内容:
$ awk 'NR>=3 && NR<=6 {print $0}' file
在关系表达式中使用正则:
$ awk --posix '$2~/go{1,5}/{print $1,$2}' file
BEGIN 块,END 块
😈 说实在的,这些东西放在 pattern 里,完全没有逻辑可言,毕竟它们算不上条件,无法进行判断,它们更像是 include,所以其实应该属于 “操作”。
BEGIN 块通常用来显示 表头。
$ awk 'BEGIN{print "Album","Artist","Title"} {print $1,$3,$5} END{print "aaa","ccc","ddd"}' music
操作
- 操作由一个或多个命令、函数、表达式组成,之间由换行符或分号隔开。
- 所有操作的最外层必须用大括号
{ }引用。 - 在操作中使用 位置变量 时,不能用双引号 引用,即
"$1",会被当作普通字符串看待。
操作中使用的元素有:
- 变量或数组 :
$3、ant[3] - 输出命令 :
print - 内建函数 :
split()、length() - 控制流语句 :
if、while
简单操作
大括号中只有一个命令,如输出:
$ awk '{print $2}' file
简单操作的组合
可以把多个命令都放在一对大括号中,用分号 ; 分隔开:
$ awk '{print $1; print $3; print $5}' file
也可以把每个命令放在单独的一对大括号中,再把所有大括号直接连接在一起:
$ awk '{print $1} {print $3} {print $5}' file
流控制语句
通过使用流控制语句,进行基于条件的操作。
if 语句常规结构
在多数编程语言中,如 JS,if 语句的结构是这样的:
if (...)
{
actions
}
将其写到一行:
if (...) { actions }
AWK 中的 if 语句结构
AWK 在操作中沿用了这个格式,因此在操作中使用控制语句是这样的:
$ awk '{if(...){actions}}' file
如:
$ awk '{if(NR==1) {print $1; print $2}}' file
if...else...
与 if 的用法一样,if...else... 以及 if...elseif...else 都可以这样使用。
if(...) {actions} else {actions}
if(...) {actions} else if(...) {actions} else {actions}
如:
$ awk -F: '{if($3<1000) {print $1,"系统用户"} else{ print $1,"普通用户"} }' /etc/passwd
root 系统用户
bin 系统用户
neo 普通用户
$ cat shit
罗大佑:88
崔健:40
窦唯:20
$ awk -F: 'BEGIN{print "姓名\t\t年龄"} \
> {if($2<=30) {print $1 "\t\t青年"} \
> else if($2>30 && $2<50) {print $1 "\t\t中年"} \
> else{print $1 "\t\t老年"}}' shit
姓名 年龄
罗大佑 老年
崔健 中年
窦唯 青年
操作中省略 { }
如果控制语句中的操作命令只有 一个,则可以 省略 命令外面的 大括号:
$ awk '{if(NR==1) print $2 }' file
循环控制语句
语法基于以下循环语句的结构:
for(初始化; 布尔表达式; 更新) {actions}
for(变量 in 数组) {actions}
while( 布尔表达式 ) {actions}
do {actions} while(条件)
for 循环
$ awk 'BEGIN{ for(i=1;i<=6;i++) {print i}}'
1
2
3
4
5
6
while 循环
$ awk -v i=1 'BEGIN{while(i<=4){print i;i++}}'
1
2
3
4
$ awk 'BEGIN{i=1;while(i<=4){print i;i++}}'
1
2
3
4
do ... while 循环
$ awk 'BEGIN{i=1;do{print "test";i++}while(i<1)}'
test
$ awk 'BEGIN{i=1;do{print "test";i++}while(i<=3)}'
test
test
test
跳出循环
continue 跳出当前循环,break 跳出整个循环。
$ awk 'BEGIN{for(i=0;i<6;i++){if(i==3){continue};print i}}'
0
1
2
4
5
$ awk 'BEGIN{for(i=0;i<6;i++){if(i==3){break};print i}}'
0
1
2
退出脚本
如果使用了 END,exit 便不是退出 awk,而是直接跳转去执行 END:
$ awk 'BEGIN{print "start";exit} {print $0} END{print "over"}' file
start
over
如果没有使用 END,exit 导致退出 awk,不再执行其余命令。
$ awk 'BEGIN{print 1;exit;print 2;print 3}'
1
跳过某行
使用 next 命令,让 awk 可以跳过当前行不处理,直接开始处理下一行:
$ cat shit
1
2
3
$ awk '{if(NR==2){next};print $0}' shit
1
3
分隔符
awk 默认使用空格、制表符做为输入和输出的字段分隔符。
输入字段分隔符
Field Separator,由内建变量 FS 表示。
$ echo "This-is-how-it-works" | awk 'BEGIN{RS="-"}{print $3}'
how
输出字段分隔符
Output Field Separator,由内建变量 OFS 表示。
$ echo "This,is,how,it,works" | awk 'BEGIN{FS=",";OFS=" _ "}{print $1,$4}'
This _ it
如果输出的格式表达式中使用了 逗号 来分隔,在输出中对应地会在该位置用 OFS 来分隔。
输入行分隔符
Row Separator,由内建变量 RS 表示。
$ echo "This is how it works" | awk 'BEGIN{RS=" "}{print $0}'
This
is
how
it
works
awk 在处理行时,只要遇到空格就换行,导致输出行中每行只有一个单词。
#### 输出行分隔符
Output Record Separator,由内建变量 ORS 表示。
df | awk 'BEGIN{ORS=" "}{print $5}'
Use% 62% 0% 1% 2% 0% 18% 1% 1% 0%
数组
AWK 中使用的数组,本质上是 关联数组,索引不仅可以用 “数字”,还可以用 “任意字符串”。
数组赋值
数组 无需声明,可以直接为数组中的元素赋值:
$ awk 'BEGIN{ ant[0]="a";ant[1]="b";ant[2]="c"; {print ant[1]} }'
判断数组元素是否存在
直接 引用 一个数组中 不存在 的元素时,awk 会 自动创建 这个元素,并且为其赋值为 空字符串。称之为引用时创建。
语法:if(索引 in 数组名) 或 if(!(索引 in 数组名))
$ awk 'BEGIN{ ant[0]="a";ant[1]="b";ant[2]="c"; if(1 in ant) \
> {print ant[1]} }'
b
用字符串索引
$ awk 'BEGIN{ ant["lipi"]="aabb";ant["coco"]="3fsd";ant["nike"]="shit";\
> print ant["coco"]}'
3fsd
删除数组
$ awk 'BEGIN{ ant["lipi"]="aabb";ant["coco"]="3fsd";ant["nike"]="shit";\
> print ant["lipi"]; delete ant; print ant["coco"] }'
aabb
删除数组元素
$ awk 'BEGIN{ ant["lipi"]="aabb";ant["coco"]="3fsd";ant["nike"]="shit";\
> print ant["lipi"]; delete ant["coco"]; print ant["coco"] }'
aabb
输出数组所有元素
$ awk 'BEGIN{ ant[1]="aabb";ant[2]="3fsd";ant[3]="shit";for(i=1;i<=3;i++) \
> {print i,ant[i]}; }'
1 aabb
2 3fsd
3 shit
$ awk 'BEGIN{ ant["lipi"]="aabb";ant["coco"]="3fsd";ant["nike"]="shit";\
> for(i in ant) {print ant[i] }}'
shit
aabb
3fsd
关联数组 打印出来的元素是 无序 的,因此与赋值时顺序不一样。
范例
范例一
利用数组来统计日志文件中每个 IP 地址 出现的次数。
假设日志文件的内容如下:
$ cat testlog
192.168.1.11
192.168.1.1
192.168.1.8
192.168.1.1
192.168.1.88
192.168.1.10
192.168.1.1
知识准备
awk 在使用数组时,有一个有意思的现象可以利用:
- 先给一个 变量 a 赋值 字符串,如果把该变量做 自加操作 的话,初始的变量值,即字符串,会被 当作数字 0 参与运算:
$ awk 'BEGIN{ a="test";print a;a=a+1;print a;a++;print a}'
test
1
2
- 如果变量的初始值为 空 的字符串,也会被当作数字 0 来处理,结果一样:
$ awk 'BEGIN{ a="";print a;a=a+1;print a;a++;print a}'
1
2
编程思路
直接引用一个数组中不存在的元素时,awk 会自动创建这个元素,并且为其赋值为 空字符串。
把日志中每个不同的 IP 地址 ,即每个字段做为数组的 索引。
同一个字段第一次出现时,该数组元素的索引是 IP 地址;第二次出现,将该数组元素进行 自加 一次,值变成数字 0,并加 1;依此类推。
统计完毕时,该地址出现了多少次,该数组元素的值就是多少。
实现思路
因为日志做了简化,每个 $1 即是 IP 地址。
因为每行数据都要处理,因此不需要模板,可以省略。
在主体程序块中只需一句变量自加的语句即可,count[$1]++。
在结尾时可以用循环语句把每个 IP 地址出现的次数一一列出,放在 END 即可。
$ awk '{count[$1]++} END{for(i in count){print i,"\t",count[i]}}' testlog
192.168.1.8 1
192.168.1.10 1
192.168.1.11 1
192.168.1.88 1
192.168.1.1 3
范例二
上面这个方法非常适合于统计 字符串出现的次数,因此如果是字符串,要怎么来统计?
$ cat testfile
human: water rice meat fruit
monkey: fruit water
goat: water grass
rabbit: water grass fruit
lion: water meat
因为数据结构不太一样了,所以我们要重新考虑一下。
- 鉴于每一行的单词数不一样,我们可能会用到变量
NF,即每记录的字段总数。 - 要想为每个记录的所有字段迭代的话,还需要循环语句。
- 同样是把每个单词做为数组的索引
$ awk '{for(i=1;i<=NF;i++){count[$i]++}} END{for(j in count){print j,"\t",count[j]}}' testfile
lion: 1
water 5
meat 2
fruit 3
rice 1
human: 1
goat: 1
rabbit: 1
grass 2
monkey: 1
范例三
数组在 AWK 中使用时,特别适用于处理 重复的行,无论这些行是否相邻。
虽然 uniq 可以去掉相邻的重复行,但对于不相邻的就无能为力了。
过滤重复的行
重复的行只显示一次:
$ awk '{ if (!a[$0]) print $0; a[$0]++ }'
可以 简写 为:
$ awk '!a[$0]++' file
此处省略了操作,因此 AWK 默认会使用 print。
过滤空行
不显示空行:
$ awk 'NF' file
只显示重复的行
$ awk 'c[$0]++; c[$0]==2' shit
内建函数
AWK 为程序开发者提供了丰富的内建函数。
算术函数
取整函数
$ awk 'BEGIN{print int(3.14)}'
3
随机数函数
rand 的功能是随机返回一个 0 到 1 的小数。
但如果单独使用时,一次生成的值是不变的:
$ awk 'BEGIN{print rand()}'
0.237788
$ awk 'BEGIN{print rand()}'
0.237788
虽然一次可以生成多个不同随机数,但下一次运行你会发现,生成的还是这些。rand 每一次都是使用同一个种子开始计算随机数,如此设计是为了便于调试代码,因为每次运行都可以生成同样的随机序列。但是,如果希望每次运行都生成不同的随机序列,需要让 rand 每次使用不同的种子,可以借助 srand 来完成。
0~1 之间的小数
$ awk 'BEGIN{srand();print rand()}'
这样就可以确保每次运行该命令时,得到的一定是不同的随机数。
小于 100 的整数
$ awk 'BEGIN{srand();print int(100*rand())}'
字符串函数
替换文本
gsub
gsub(原字符串, 新字符串, 正文)
global substitution,正文中的原字符串,会被 全部 替换成新字符串,如果正文省略,则会默认使用 $0。
把 l 替换成 L:
$ awk '{gsub("l","L",$0);print $0}' test
HeLLo WorLd !
把第一个字段中的小写字母替换成数字 8:
$ awk '{gsub("[a-z]","8",$1);print $0}' test
H8888 World !
sub
sub 功能与 gsub 相似,只不过它只会替换第一个匹配,而非全部。
$ awk '{gsub("l","L",$0);print $0}' test
HeLlo World !
字符串长度
length() 用于获取字符串的长度:
$ cat p
Hello World !
What Are You Doing?
$ awk '{for(i=1;i<=NF;i++){print $i,length($i)}}' test
Hello 5
World 5
! 1
What 4
Are 3
You 3
Doing? 6
如果省略传入的参数,则默认把 $0 做为参数:
$ awk '{print $0,length()}' test
Hello World ! 13
What Are You Doing? 19
输入控制
READ
从标准输入中读取一行。
read [ -p ][ -r ][ -s ][ -u[ n ] ] [ VariableName?Prompt ] [ VariableName ... ]
read 命令从 标准输入 中读取 一行,并将输入行的 每个字段的值 指定给 特定变量,用 IFS(内部字段分隔符)变量中的字符作为 分隔符。
read 后面的变量可以有 一个或多个,如果输入多个字段,则第一个字段给第一个变量,第二个字段给第二个变量,如果输入字段数量过多,则最后剩下的所有字段都给最后一个变量。
如果没有指定变量名,读取的数据将被自动赋值给特定的变量 REPLY。
范例
read 1987name
从标准输入读取输入并赋值给变量1987name。
read first last
从标准输入读取输入到第一个空格或者回车,将输入的第一个单词放到变量first中,并将该行其他的输入放在变量last中。
read
从标准输入读取一行并赋值给特定变量REPLY。
read -a arrayname
把单词清单读入arrayname的数组里。
read -p "text"
打印提示(text),等待输入,并将输入存储在REPLY中。
read -r line
允许输入包含反斜杠。
read -t 3
指定读取等待时间为3秒。
read -n 2 var
从输入中读取两个字符并存入变量var,不需要按回车读取。
read -d ":" var
用定界符“:”结束输入行。
输出控制
块操作
tee
读取标准输入,输出一份到标准输出,一份到文件。
常用于把输入 另存 为文件。

tee -a file
-a 追加到文件
范例
last | tee last.list | cut -d " " -f 1 另存一份
ls -l /home | tee -a ~/homefile | less 追加到文件
cat
把一个或多个文件或标准输入合并在一起,发送给标准输出。
cat [OPTION]... [FILE]...
-v 显示不可打印字符
-E 显示行尾符 $
-T 显示 tab 键,用 ^I表示
-A 相当于 -vET
-b 非空行显示行号
-n 所有行显示行号
tac
功能与 cat 一致,只不过是反向显示,首行变末行。
tac file
nl
把文件内容发送到标准输出,并在每行前面加上行号。
nl [OPTION]... [FILE]...
-b 指定行号显示方式:
`-ba` 所有行显示行号
`-bt` 非空行显示行号(默认值)
-n 指定行号对齐方式:
`-n ln` 左对齐
`-n rn` 右对齐
`-n rz` 右对齐,并用0填充空位
-w 指定行号占用的字符数
more
以翻页方式查看文件内容。
more file
每页的最后一行会显示出当前显示的百分比,还可以在最后一行输入命令:
空格 向下翻一页
回车 向下翻一行
/字符串 向下查找关键字
:f 立刻显示出文件名以及目前显示的行数;
q 立即退出 more
b 往回翻页,对管道不起作用
less
less file
可以输入的命令:
空格 向下翻一页;
pagedown 向下翻一页;
pageup 向上翻一页;
/字符串 向下查找
?字符串 向上查找
n 重复查找
N 反向重复查找
g 到第一行
G 到最后一行
q 退出
head
-n 显示的行数,缺省时默认显示 10 行
head -n 6 file 显示前6行
head -n -6 file 去掉后6行,显示剩下的所有
tail
tail -n 6 file 显示后 6 行
tail -n +10 file 去掉前 10 行,显示剩余的行
tail -f log 持续监测 log 文件,一旦有新内容追加,马上显示出来
od
把输入 转换 为 八进制 或其它格式,发送到标准输出。
od 命令用指定格式显示由 File 参数指定的文件。如果 File 参数没有给定,od 命令读取标准输入。
在第一个语法格式中,输出格式是由 -t 标志指定。如果没有指定格式类型,-t o2 是缺省值。
在第二个语法格式中,输出格式由标志组合指定。Offset 参数指定了文件中文件输出的开始点。缺省情况下,Offset 参数解释为八进制字节。如果附加了 . 点后缀,参数解释为十进制的;如果参数前导以 x 或 0x 开始,处理为十六进制。 如果 b 后缀添加到参数,解释为块是 512 字节;如果 B 后缀添加到参数上,解释为块是 1024 字节。
Label 参数解释为首字节显示的伪地址。如果使用了该参数,它在 () 括号中给出,遵循 Offset 参数。相对于 Offset 参数,后缀有同样的意义。
当 od 命令读取标准输入时,Offset 参数和 Label 参数前头必须有个 +(加号)。
环境变量的设置如 LANG 和 LC_ALL 影响着 od 命令的操作。
使用 类型字符串 来格式化输出以显示文件:
od [ -v ] [ -A AddressBase ] [ -N Count ] [ -j Skip ] [ -t TypeString ... ] [ File ... ]
要使用 标志 来格式化输出以显示文件:
od [ -a ] [ -b ] [ -c ] [ -C ] [ -d ] [ -D ] [ -e ] [ -f ] [ -F ] [ -h ] [ -H ] [ -i ] [ -I ] [ -l ] [ -L ] [ -o ] [ -O ] [ -p ] [ -P ] [ -s ] [ -v ] [ -x ] [ -X ] [ [ -S [ N ] ] [ -w [ N ] ] [ File ] [ [ + ] Offset [ . | b | B ] [ + ] Label [ . | b | B ] ] [ File ... ]
-t 后面可以接各种类型的输出
a 利用默认的字符来输出
c 使用 ASCII 字符来输出
d[size] 用十进制输出数据,每整数占用的字节数
f[size] 用浮点数值输出数据,每整数占用的字节数
o[size] 用八进制来输出数据,每整数占用的字节数
x[size] 用十六进制输出数据,每整数占用的字节数
范例
od -t c file
以 ASCII 方式来查看文件内容
od -t oCc file
以 8 进制列出储存值与 ASCII 的对照表
printf
格式化输出
printf 命令模仿 C 程序库(library)里的 printf() 程序。
printf 由 POSIX 标准所定义,因此使用 printf 的脚本比使用 echo 移植性好。
printf 不是管道命令,无法直接读取标准输入,需要 把文件内容先读取出来,作为 printf 的处理对象。而且处理时 不会自动换行,必须手动在格式中加入换行符,否则所有内容都显示在一行。
语法
printf FORMAT [ARGUMENT]...
FORMAT
FORMAT 格式字符串,用来描述输出的排列方式,需用 引号 括起来。
此字符串包含 按字面显示的字符 以及 格式替代符。
一般字符按字面显示,转义序列需解释后再输出成对应的字符。
- 格式替代符
格式替代符是特殊的占位符,用来描述如何显示对应的参数。
格式替代符由两部分组成:% + 指示符。
%s 字符串
%d, %i 十进制整数
%b 相对应的参数被视为含有要被处理的转义序列字符串
%c ASCII字符。显示相对应参数的第一个字符
%e, %E, %f 浮点格式
%g %e 或 %f 转换,看哪一个较短,则删除结尾的零
%G %E 或 %f 转换,看哪一个较短,则删除结尾的零
%o 不带正负号的八进制值
%u 不带正负号的十进制值
%x 不带正负号的十六进制值,使用 a~f 表示 10~15
%X 不带正负号的十六进制值,使用 A~F 表示 10~15
%% 字面意义的 %
%8s 总长 8 位,字符串
%8i 总长 8 位,整数
%8.2f 整数 8 位,小数点后2位
- 转义序列
\a 警告声
\b 回退键
\f 换页
\n 换行
\r 回车
\t 水平制表符
\v 垂直制表符
\xNN 两位数字,查询 ASCII
arguments
是与格式替代符相对应的参数列表,如一系列的 字符串或变量值。
范例
- 仅列出姓名与成绩,用 tab 分隔
printf '%s\t %s\t %s\t %s\t %s\t \n' $(cat printf.txt)
%s 代表一个不固定长度的字串,而字串与字串中间以 \t 来分隔。
- 第二行以后,分别以字串、整数、小数点来显示:
printf '%10s %5i %5i %5i %8.2f \n' $(cat printf.txt | grep -v Name)
查 ASCII 对照
- 16 进制的 45 对应 ASCII 的哪个字符?
printf '\x45\n'
E
wc
统计 文件的字符数、行数、单词数。
wc -lwm
-l 行数
-w 单词数
-m 字符数
范例
- 统计字、行、字符数
cat /etc/man_db.conf | wc
131 723 5171 # 默认同时列出行数、单词数、字符数
- 分析 last 输出信息,计算登陆系统的总人次
last 最后两行并非帐号内容,分别以 reboot 和 wtmp 开头,另外还有一行以(unknown开头的行也是无用行,因此需要去掉这三行及空行。
last | grep [a-zA-Z] | grep -v 'wtmp' | grep -v 'reboot' | grep -v 'unknown' |wc -l
先取出非空行,然后去除上述关键字那三行,再计算行数。
行操作
sort
sort 命令用于 给行排序,可以按不同的数据型态(如数字或文字)来排序。
排序的字符与 语系 的编码有关,因此,排序时建议使用 LANG=C 来统一语系。
sort 默认按每行第一个字符,按字母顺序排序。
sort -fbMnrtuk file or STDIN
-f 忽略大小写
-b 忽略前置空白字符
-M 根据月份英文名字排序
-n 用纯数字排序
-r 反向排序
-u 相同的数据仅保留一行(去重复)
-t 分隔符,默认用 [tab] 分隔
-k 切割之后,依据第几段排序
范例
cat /etc/passwd | sort # 按第一段(帐号)排序
cat /etc/passwd | sort -t ':' -k 3 -n # 按第三段排序
last | cut -d ' ' -f 1 | sort # 按第一段排序
last | cut -d ' ' -f 1 | sort -u # 去掉重复项
uniq
查找省略 连续重复 的行。
uniq -ic
-i 忽略大小写
-c 统计重复次数
范例一
查看登陆次
| 用 last 列出历史登陆记录 | 只保留帐号栏 | 去掉 unknown | 去掉 reboot | 排序 | 去掉重复项并统计重复次数 |
$ last | cut -d ' ' -f 1 | grep -v 'unknown' | grep -v 'reboot' | sort | uniq -c
1
66 liloli
5 neo
10 root
1 wtmp
范例二
$ cat shit
human: water rice meat fruit
monkey: fruit water
monkey: fruit water
monkey: fruit water
monkey: fruit water
monkey: fruit water
monkey: fruit water
goat: water grass
monkey: fruit water
rabbit: water grass fruit
lion: water meat
$ uniq shit -c
1 human: water rice meat fruit
6 monkey: fruit water
1 goat: water grass
1 monkey: fruit water
1 rabbit: water grass fruit
1 lion: water meat
cut
把文件的每一行 截取一部分,发送给标准输出。
cut [options] strings
-d 指定分隔符
-f 按段截取,接范围
-c 按列截取,接范围
cut 主要的用途在于 截取 文本文件或标准输入中,每一行里的指定 字符串。
cut -d '分隔符' -f fields
有特定 分隔符 的文件,截取 某几段
cut -c 字符区间
用于 排列整齐 的文件,截取 某几列
截取指定段
echo ${PATH} | cut -d ':' -f 5 取第5个值
echo ${PATH} | cut -d ':' -f 3,5 取第3、第5个值
echo ${PATH} | cut -d ':' -f 3-5 取第3到第5个值
last | cut -d ' ' -f 1 last 输出的信息只保留用户名
截取指定列
export | cut -c 12- 截取第 12 列之后的字符
export | cut -c 12-20 截取第 12-20 列的字符
export | cut -c -20 | head -n 6 截取第 20 列之前的字符
export | cut -c 1-5,20,30-35 | head -n 6 截取指定列的字符
join
join 把两个文件的 相关连的行连接在一起。
使用 join 之前,应该先把文件内容排序。
join [-ti12] file1 file2
-t 分隔符
-i 忽略大小写
-1 第一个文件的关键字段
-2 第二个文件的关键字段
join 默认分隔符为 空格,比较 第一个字段,如果相同,就把两个文件的这两行数据连接在一起。
范例
- 把 /etc/passwd 与 /etc/shadow 同一用户的数据整合至一行
join -t ':' /etc/passwd /etc/shadow | head -n 3
# 因为两文件关键字段均为第一段,故省略不写 -1,-2
root:x:0:0:root:/root:/bin/bash:$6$wtbCCce/PxMeE5wm$KE2IfSJr...:16559:0:99999:7:::
bin:x:1:1:bin:/bin:/sbin/nologin:\*:16372:0:99999:7:::
daemon:x:2:2:daemon:/sbin:/sbin/nologin:\*:16372:0:99999:7:::
🚩 连接时,第二个文件的第一字段被删除,避免重复。
- 整合 /etc/passwd 和 /etc/group,关键字为 GID
GID 为 /etc/passwd 的第4段,为 /etc/group 的第3段
join -t ':' -1 4 /etc/passwd -2 3 /etc/group | head -n 3
0:root:x:0:root:/root:/bin/bash:root:x:
1:bin:x:1:bin:/bin:/sbin/nologin:bin:x:
2:daemon:x:2:daemon:/sbin:/sbin/nologin:daemon:x:
# 连接时,GID 被提到行首,并删除原始位置上的 GID
paste
paste 不检查文件内容,把 多个文件相同的行合并在一起,中间用 tab 分隔,输出到标准输出。
paste [-d] file1 file2 ...
-d 分隔符,默认为 tab
- 代替 STDIN
- 拼合
/etc/passwd和/etc/shadow
paste /etc/passwd /etc/shadow
root:x:0:0:root:/root:/bin/bash root:$6$wtbCCce/PxMeE5wm$KE2IfSJr...:16559:0:99999:7:::
bin:x:1:1:bin:/bin:/sbin/nologin bin:\*:16372:0:99999:7:::
daemon:x:2:2:daemon:/sbin:/sbin/nologin daemon:\*:16372:0:99999:7:::
- 输出 /etc/group,然后与上例连在一起,取前三行
cat /etc/group | paste /etc/passwd /etc/shadow - | head -n 3
# - 代表 STDIN ,即 cat /etc/group的输出 ^
字符串操作
这里的工具要么是处理简单的字符串,要么是把整个文件内容做为一个大的字符串,或是一个文本流来一起处理。
tr
可以对来自标准输入的 单个字符 进行 替换、压缩 和 删除。
语法
tr [OPTION] SET1 [SET2]
SET1 为查找的对象,SET2 为替换的内容,除普通的 字符串,它们还支持 字符类 表示,如 [:lower:]、[:space:]。
SET1 中的字符串在操作时会按单个字符来查找,如 'hold' 不会去查找 hold 这个单词,而是去查找 h、o、l、d 这些单个的字符,如果是删除就只删除这些单个的字符,如果是替换则只替换成 SET2 中相同位置的单个字符。SET1 'abc',SET 2 'xyz',则所有字母 a 被换成 x,依此类推。
[OPTION]
条件类:
-c 查找对象为 SET1 中各个 字符的补集。-c 'ab\n' 代表除 a、b、换行符以外的所有字符。
-t 如果 SET1 的字符数比 SET2 的多,则先把 SET1 切成同样多的,再操作。
操作类:
-d 删除 SET1,此时会忽略 SET2
-s 把连续重复的字符以单独一个字符表示,压缩 成一个
[SET1] 和 [SET2] 代表是用
字符类
[:alnum:]:字母和数字
[:alpha:]:字母
[:cntrl:]:控制(非打印)字符
[:digit:]:数字
[:graph:]:图形字符
[:lower:]:小写字母
[:print:]:可打印字符
[:punct:]:标点符号
[:space:]:空白字符
[:upper:]:大写字母
[:xdigit:]:十六进制字符
小写字母 换 大写字母
$ last | tr '[a-z]' '[A-Z]'
$ tr '[:lower:]' '[:upper:]'
花括号 换 圆括号
$ tr '{}' '()' < inputfile > outputfile
空白字符 换 制表符
$ echo "This is for testing" | tr [:space:] '\t'
压缩连续的空格
$ echo "This is for testing" | tr -s [:space:] '\t'
删除冒号
$ cat /etc/passwd | tr -d ':'
删除所有数字
$ echo "my username is 432234" | tr -d [:digit:]
my username is
删除所有非数字
$ echo "my username is 432234" | tr -cd [:digit:]
432234
col
col 是一种文本过滤器,它可以过滤来自标准输入或文件的文本。它会尝试 删除 文本中的 RI (逆向换行符),并把 空格 替换 成 tab 。
col -xb
-x 把 tab 键转换成空格
- 用 cat -A 显示所有特殊字符,把 tab 换成空格
cat -A /etc/man_db.conf 此时会看到很多 ^I 的符号,那就是 tab
cat /etc/man_db.conf | col -x | cat -A | more
expand
expand 用多个空格替换 tab
expand [-t] file
-t 替换空格的个数
grep '^MANPATH' /etc/man_db.conf | head -n 3 | expand -t 6 - | cat -A
unexpand
把空格转换成 tab
用法同 EXPAND。