
简介
netfilter
在 Linux 2.4.x 以后的版本中,netfilter 是一款用于进行数据包过滤的框架,该框架中的软件有以下功能:
- 网络地址转换
- 数据包内容修改
- 数据包过滤
netfilter 是 Linux 内核 中的一系列的 钩子,内核模块可以通过它们与协议栈注册回调函数,然后为每一个穿越对应钩子的数据包回调函数。iptables 通过与 netfilter 框架中的各种钩子进行交互,来实现防火墙的各种功能。
每个进入网络系统的数据包,无论出站还是入站,都会触发这些钩子,注册了这些钩子的程序,会在关键点上与数据流量进行交互。与 iptables 相关的内核模块,在这些钩子上注册,以确保流量符合防火墙规则所规定的条件。
netfilter 钩子
有 5 个 netfilter 的钩子可以让程序注册。当数据包通过堆栈时,它们会触发已在这些钩子上注册的内核模块。数据包会触发的钩子取决于数据包是入站的还是出站的,数据包的目标以及数据包在上一个点是否被丢弃或拒绝。
以下的钩子代表各个预定义的协议栈中的关键点:
NF_IP_PRE_ROUTING: 入站流量进入协议栈之后,会触发这个钩子,该钩子会在进行任何路由决策之前进行处理。NF_IP_LOCAL_IN: 入站数据包被路由之后,如果它的目标是本机,就会触发这个钩子。NF_IP_FORWARD: 入站数据包被路由之后,如果它的目标是另一台主机,就会触发这个钩子。NF_IP_LOCAL_OUT: 本地产生的出站流量到达协议栈时,会触发这个钩子。NF_IP_POST_ROUTING: 出站或转发流量被路由后,从本地发出之前,会触发这个钩子。
希望在这些钩子上注册的内核模块必须提供一个优先级编号,以帮助确定在触发挂钩时它们将被调用的顺序。这为多个模块 (或同一模块的多个实例) 提供了以特定顺序连接到每个挂钩的方法。每个模块会被依次调用,并将在处理后向 netfilter 框架返回一个决定,即应该如何处理该数据包。
iptables
iptables 是一个通用的 表格 结构,用于定义一系列的 规则。表格中的每条规则由若干个 匹配 和一个 关联动作 组成。
“netfilter,ip_tables(内核中的数据包过滤器),连接追踪,网络地址转换” 共同组成了 netfilter 框架的主要部分。
iptables 一词通常是指 Linux 内核 中的防火墙,该防火墙是 netfilter 的一部分。iptables 是一个 用户空间 的程序,用来配置内核防火墙。因此,我们平时所说的 iptables 实际上指的是 netfilter/iptables,即框架中防火墙部分与前端的组合。
针对不同的协议使用不同的内核模块。如 IPv4 使用 iptables,IPv6 使用 ip6tables,ARP 使用 arptables,以太帧使用 ebtables。
iptables 需要 root 权限来运行。通常安装于 /usr/sbin/iptables 目录。
虽然可以使用 service iptables start 启动,但准确的来说,iptables 没有守护进程,因此不是真正意义上的服务,只是内核提供的功能。
iptables 的继任者为 nftables,在内核版本 3.13 之后合并到 mainline。
IP 过滤器
IP Filter
iptables 是一个 IP 过滤器。
根据定义,IP 过滤器主要工作于 TCP/IP 协议栈的二层,不过 IP 过滤器是有能力在三层工作的,当今的大多数 IP 过滤器也大多工作于三层。在对定义实现的范围,不会严格遵守定义。
iptables 的工作是基于网络层与传输层的包头。iptables 和 netfilter 主要工作于网络层和传输层,它们所关注的协议主要为 IP、TCP、UDP、ICMP。
连接追踪
IP 过滤器不会跟随数据流,这样做太耗费 CPU 和内存,它只会 追踪大量的数据包,观察它们是否属于同一个数据流,这个行为称为连接追踪。就是因为有了连接追踪,我们才得以实现地址转换以及数据包状态匹配。
iptables 没有能力把不同的数据包中的数据连到一起,因此它任何时候都无从知道数据的真实内容。它更没有能力针对数据包中的内容进行匹配和过滤。
IP 过滤相关名词
丢弃
Drop/Deny
丢弃数据包。
如果数据包被 Drop 或 Deny,其实就是被 删除 了,不会采取别的操作。
没人会告诉发送端的主机数据包被丢弃了,接收端也不会知道。数据包就直接 消失 了。
拒绝
Reject
拒绝数据包。
也是被 删除 了,但会 告知发送端。
拒绝数据包之后,会给发送端回复一条消息告知。
接受
Accept
接受数据包,允许其穿越防火墙规则。
数据包状态
State
某个数据包与整个数据流相比,它属于什么状态。数据包的状态是通过连接追踪系统获取的。
如果某数据包是防火墙看到的第一个包,如 TCP 连接中的 SYN 数据包,则认为其状态为 new。
如果某数据包属于一个已建立的连接,防火墙已经认识这个连接了,则该数据包的状态为 established。
规则链
Chain
规则链包含一系列的规则,应用于那些穿越该链的数据包。
每个规则链都有其专门的目的及适用的范围。
- 目的:它应该连接到哪个表格,也就决定了该链的用途。
- 范围:只针对转发的数据包,还是只针对入站的数据包。
表格
Table
每个表有着专门的用途,共有 4 张表:raw,nat,mangle,filter。
filter 表格专门用于过滤数据包,nat 表格专用于为数据包进行地址转换。
匹配
该词通常有两个不同的意思:
- 一个具体的匹配:如源地址匹配某网段或网址。
- 一条规则整体的匹配:如果数据包匹配整条规则,会对其执行相应的操作,即 jump 或 target 指令。
因为一条规则可以有多个具体的匹配,所以整体的匹配可能意味着同时匹配多个条件。
目标
Target
通常每条规则都会配置一个目标,即如果数据包完全满足该条规则时,应该对其进行什么 操作。
如,目标可以是丢弃、接受、地址转换等。
规则
Rule
规则由一个或多个 匹配 和一个 目标 组成。
规则集
Ruleset
规则集是指在 filter,nat,raw,mangle 表格中的所有规则的集合,以及之后产生的规则链中的规则。
大多数时间,规则集是写在一个配置文件中的。
跳转
Jump
跳转指令与 目标 是紧密相关的。跳转指令的书写方式与目标是一样的,唯一的区别是,跳转指令使用的不是目标的名称,而是另一条规则链的名称。
如果匹配规则,数据包会被 发送到另一条规则链来处理。
连接追踪
Connection Tracking
防火墙如果具有连接追踪功能,它就有能力追踪连接或数据流。但是,连接追踪会消耗一定的 CPU 与内存资源。
策略
Policy
如果没有规则能匹配数据包,防火墙应该采取的 默认行为。
IP 过滤器的部署
在使用防火墙时,我们通常会按两种方式来部署,即黑名单与白名单。
白名单
默认丢弃所有数据包,只有匹配规则的允许通过。
黑名单
默认接受所有数据包,只有匹配规则的会被丢弃。
白名单相对来说更加安全,但需要更多的。
网络地址转换
NAT:Network Address Translation
要想使用 NAT 功能,无需 Cisco PIX ,iptables 就可以实现。
NAT 简介
通过 NAT 可以让一台或多台主机共享同一个 IP 地址。
NAT 服务器可以把数据包的源地址、目的地址转换成其它的地址。
SNAT
Source Network Address Translation
在实际生产中,公共 IP 地址资源极其有限。因此,在本地网中的多个主机可以使用不同的私网地址。为本地网络打开 SNAT 服务之后,SNAT 会把所有的私有地址转换成公司自己的公共 IP 地址。
DNAT
Destination Network Address Translation
DNAT 更适用于多个服务器。
一方面,节省了公共 IP 资源;另一方面,可以在代理服务器与后端服务器中间,很容易地建立起一个难以穿透的防火墙。也可以让多个服务器共享一个公共 IP 地址。
穿越表格与规则链
数据包是是以什么样的顺序、如何穿越不同的表格和规则链的?一个数据包首次抵达防火墙时,网络设备收到并它传递给内核中对应的设备驱动程序。数据包开始一系列的穿越,最后,它要么是被发送给适当的本地应用程序,要么被转发给其它主机。
规则的类别:iptables 使用表格来组织规则。根据所用来制定决策的类型,这些表格把规则分为不同的类别。
例如,如果某条规则是用来处理网络地址转换的,它会被放置于 nat 表格。如果规则是用来决定是否允许数据包继续向目标传递的,可能会置于 filter 表格。
规则链:在每个 iptables 表格中,所有的规则又进一步被置于独立的规则链中。每个表格所承载的规则都有不同的用途,正是该用途定义了表格。内置的规则链代表了触发它们的 netfilter 钩子。规则链基本上决定了规则将在何时被评估。
iptables 内置表格
Mangle 表格
mangle 表格主要用于修改数据包的 IP 头,如 TOS、TTL 等。
该表格还可以在数据包上做一个内核内部的标记,用于在其它表格中做进一步的处理。这个标记不会触及到真正的数据。
以下目标仅适用于 mangle 表格,不能在 mangle 表格之外使用:
- TOS
- TTL
- MARK
- SECMARK
- CONNSECMARK
Nat 表格
该表格只用于 NAT。
当数据包进入协议栈时,该表格中的规则会判断是否需要 NAT,以及如何进行,从而影响数据包及所在流量的路由。通常用于把数据包路由到无法直接访问的网络中。
只有每个连接的 第一个数据包 才会进入这张表,一旦该连接被 iptables 所识别并追踪,该连接随后的数据包会 自动采取同样的地址转换 操作。iptables 会把对当前打开的连接所做出的地址转换(即映射)保存到连接追踪表中,如 /proc/net/ip_conntrack。而且该连接 双向 的数据包都会根据已有的映射进行处理。如 DNAT 之后,数据包的源目标地址首先会被记录下来,然后才更换,当该连接的应答数据包返回时,会用之前记录的源目标地址做为其源地址。
而真正完成这些工作的目标为:
- DNAT
- SNAT
- MASQUERADE
- REDIRECT
Raw 表格
raw 表格的功能特别单一,即标记数据包,使其不会被连接追踪系统处理。该功能是由 NOTRACK 目标实现的。
如果连接撞到 NOTRACK 目标,就不会对其进行追踪。
该表中只有 PREROUTING 和 OUTPUT 链。
iptables 防火墙是区分状态的,意味着评估数据包时会考量它与之前数据包的关系。连接追踪是建立在 netfilter 框架上的,iptables 会把数据包做为当前连接或会话的一部分来看待,并不会将其视为离散的、不相关的数据包。连接追踪的逻辑在数据包抵达网络接口之后不久就开始应用了。
Filter 表格
过滤表主要用于过滤数据包。它是使用最多的表格。
该表格用于判断是否允许数据包继续向其目标前行。可以对匹配的数据包进行过滤。在这里可以查看数据包里包含什么内容,根据需要决定丢弃还是接受。平时我们所讨论的防火墙的功能,大部分由该表格实现。
几乎所有的目标在此表格都能使用。
有些内核还有第五张表格,即 Security 表格,用于由 SELinux 部署安全策略。
iptables 规则链
通过使用规则链,可以控制在数据包的传递路径中,应该从 哪个位置 开始评估规则。因为每张表都有多条链,所以表格的影响力可以在处理过程中的多个位置呈现。由于特定类型的决策只有在协议栈的特定位置才有意义,因此,不是每张表中都有所有的规则链。
内置规则链
内置的规则链其名称实际上反映了它们对应的 netfilter 钩子的名称:
PREROUTING: 由勾子NF_IP_PRE_ROUTING触发。路由决策之前,数据包会进入该链。不要在此链进行过滤,有些情况会被绕过。INPUT: 由勾子NF_IP_LOCAL_IN触发。进入该链的数据包会传递给本机来处理。这与开着 socket 的进程无关,本地的数据传递是由local-delivery路由表控制的。FORWARD: 由勾子NF_IP_FORWARD触发。已被路由的数据包,如果目的地不是本机,则走该链OUTPUT: 由勾子NF_IP_LOCAL_OUT触发。从本机产生的数据包走该链POSTROUTING: 由勾子NF_IP_POST_ROUTING触发。路由决策已经完成,在交给网络设备之前,数据包进入该链
只有五种 netfilter 内核钩子,因此,来自不同表格的链是注册在每个钩子上的。例如,三张表格中有 PREROUTING 链,当这些链在对应的 NF_IP_PRE_ROUTING 钩子上注册时,它们会设定一个优先级,以决定这些表格中的 PREROUTING 链应该以什么 顺序 执行,优先级最高的 PREROUTING 链最先执行。
自定义规则链
如果数据包从过滤表中进入一条规则链,如 INPUT,我们可以指定一个跳转的规则,以跳转同一张表中的另一条链上。跳转的链必须是用户自定义的,不能是系统内置的链。
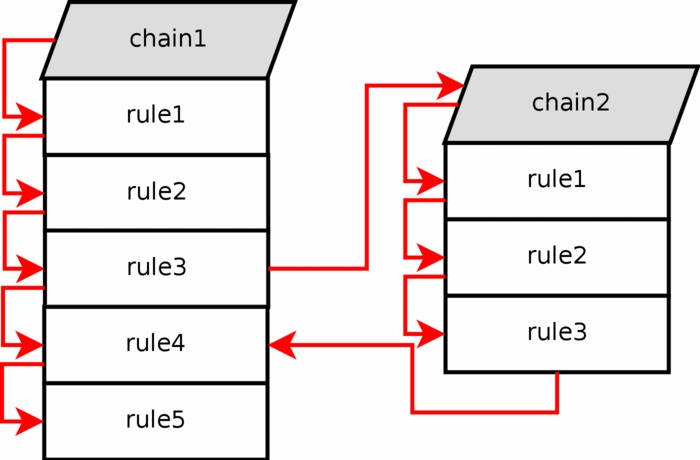
用户自定义的规则链无法在链尾定义默认策略,只有系统内置的链才可以。解决的办法是在自定义链的结尾加一条规则,针对所有不匹配的数据包,它就可以当作默认策略来使用了。自定义规则链如果没有任何匹配,默认是会跳转返回源链的。
表格与链的关系
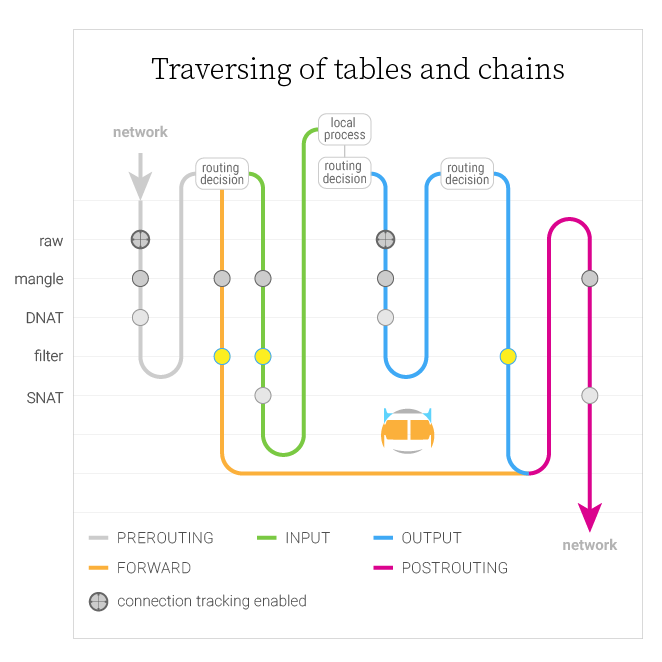
如果三个表格中都有 PREROUTING 链,它们以什么顺序进行评估呢?
下表展示了每张表中包含的各条规则链,从左至右。例如,raw 表格有 PREROUTING 和 OUTPUT 链。从上到下观察,展示了每条链是以怎样的顺序调用的。
下表中的 NAT 表被拆分为 DNAT 和 SNAT,以便于更清晰地定位其顺序。同时还加入了路由决策以及启用连接追踪的行,用以代表对应的点。
| 表格↓ / 链→ | PREROUTING | INPUT | FORWARD | OUTPUT | POSTROUTING |
|---|---|---|---|---|---|
| (路由决策) | ✓ | ||||
| raw | ✓ | ✓ | |||
| (启用连接追踪) | ✓ | ✓ | |||
| mangle | ✓ | ✓ | ✓ | ✓ | ✓ |
| nat (DNAT) | ✓ | ✓ | |||
| (路由决策) | ✓ | ✓ | |||
| filter | ✓ | ✓ | ✓ | ||
| nat (SNAT) | ✓ | ✓ |
数据包触发一个钩子时,相关的规则链开始处理,就按照上表中的顺序,从上至下。
钩子对应的是每一列,数据包会触发哪个钩子决定于它是入站还是出站的、路由决策是什么、数据包是否通过了过滤规则。
某些事件会导致表格中的某个链被跳过。例如,只有连接中的第一个数据包才会用 NAT 规则来评估,对第一个数据包做出的任何决策都会应用于连接中随后的数据包,不会对它们进行额外的评估。对于经 NAT 处理过的连接,它们会自动拥有反向 NAT 规则,以便正确路由。
规则链的穿越顺序
假设服务器了解如何路由一个数据包,而且防火墙的规则也允许其传输,以下的流程则不同情况下数据包所穿越的路径:
- 入站数据包 :
PREROUTING->INPUT - 转发数据包 :
PREROUTING->FORWARD->POSTROUTING - 本地生成的数据包 :
OUTPUT->POSTROUTING
将这些信息与上表联系起来,就得到了各种数据包所穿越的不同节点。
入站数据包
入站的数据包会经历如下的步骤,最后才会真正被传递给接收它的应用程序:
数据包的目的地为本地主机。
| 步骤 | 表格 | 规则链 | 说明 |
|---|---|---|---|
| 1 | 在互联网上传输 | ||
| 2 | 从网络设备接口进入主机 | ||
| 3 | raw | PREROUTING | 该链用于连接追踪开始之前对数据包的处理,例如可以设定一个连接,让其不会被连接追踪。 |
| 4 | 连接追踪开始 | ||
| 5 | mangle | PREROUTING | 该链通常用于修改数据包,即修改 TOS、TTL 等 |
| 6 | nat | PREROUTING | 该链主要用于 DNAT,不要在此链进行过滤,有些情况会被绕过 |
| 7 | 路由决策,本地处理还是转发 | ||
| 8 | mangle | INPUT | 使用该链修改数据包的 TOS、TTL |
| 9 | filter | INPUT | 目的为本机的数据包在此进入该链,开始接受过滤,无论从哪个接口、哪个方向进来的, |
| 10 | 把数据包交由本机处理,或发送给对应的应用程序 |
上表中的数据包只是穿越了 INPUT 规则链,并没有穿越 FORWARD 链。
出站数据包
数据包从本地主机发出。
| 步骤 | 表格 | 规则链 | 说明 |
|---|---|---|---|
| 1 | 本地处理,或应用程序 | ||
| 2 | 路由决策。应使用哪个源地址,从哪个接口出站,及其它信息 | ||
| 3 | raw | OUTPUT | 在连接追踪开始之前,对本地生成的数据包进行处理,可标记连接,对其不进行连接追踪 |
| 4 | 连接追踪开始 | ||
| 5 | mangle | OUTPUT | 修改数据包。建议不要过滤该链,会有副作用 |
| 6 | nat | OUTPUT | 该链用于从防火墙自身 NAT 出站数据包 |
| 7 | 路由决策。因为上面的 mangle 和 nat 可能改变了数据包的路由 | ||
| 8 | filter | OUTPUT | 对出站数据包进行过滤 |
| 9 | mangle | POSTROUTING | 数据包确定路由之后、出站之前,可以再次修改。穿越至防火墙的数据包和防火墙自身产生的数据包都会撞到该链。 |
| 10 | nat | POSTROUTING | SNAT 开始,建议不要过滤,因为有些数据包有可能会溜出去,即使默认策略为丢弃也没用。 |
| 11 | 从某网络接口出站 | ||
| 12 | 飞到互联网上 |
转发数据包
数据包是奔向另一主机或另一网络的:
| 步骤 | 表格 | 规则链 | 说明 |
|---|---|---|---|
| 1 | 在互联网上传输 | ||
| 2 | 从网络设备接口进入主机 | ||
| 3 | raw | PREROUTING | 可以设定一个连接,让其不会被连接追踪。 |
| 4 | 连接追踪开始 | ||
| 5 | mangle | PREROUTING | 修改 TOS、TTL |
| 6 | nat | PREROUTING | 该链主要用于 DNAT,不要在此链进行过滤,有些情况会被绕过 |
| 7 | 路由决策,本地处理还是转发 | ||
| 8 | mangle | FORWARD | 使用该链修改数据包的 TOS、TTL |
| 9 | filter | FORWARD | 对数据包进行过滤 |
| 10 | mangle | POSTROUTING | 使用该链修改数据包的 TOS、TTL |
| 11 | nat | POSTROUTING | SNAT 开始,建议不要过滤,有些数据包有可能会溜出去。伪装也是在这一步进行。 |
| 12 | 从某网络接口出站 | ||
| 13 | 飞到互联网上 |
虽然规则链很多,但是没有专门针对特定网络接口的。
跳转至自定义链
有一种特殊类型的非中止型目标:跳转目标,jump target。
跳转目标就是在评估后跳转到另一个链,进行其它的处理。
除了系统内置的链,用户还可以根据需要创建自己的链,在链中放置自定义的规则。区别在于,用户创建的链只能通过跳转来使用,因为它们没有注册自己的 netfilter 钩子。
用户自定义的链就是对调用它的链的单纯的扩展。例如,在自定义链中,如果到达规则列表结尾,或匹配的规则激活了 RETURN 目标,评估会被传回给调用它的链。当然,如果需要,还可以再次跳转到其它的自定义链上。
这种跳转的结构可以实现更加丰富的功能,并为框架提供更强健的分支。
连接追踪
conntrack
为什么需要连接追踪功能?因为它是 状态防火墙 和 NAT 的实现基础。
Linux 为每一个经过网络堆栈的数据包,生成一个新的连接条目。此后,所有属于此连接的数据包都被唯一地分配给这个连接,并标识连接的状态。连接追踪是防火墙模块的状态检测的基础,同时也是地址转换中实现 SNAT 和 DNAT 的前提。
内核使用 nf_conntrack 模块来追踪 iptables 网络包的状态,该模块同时支持无状态协议与有状态协议,它独立于 NAT 模块运行,但其主要目的是为了支持 NAT 模块。
借助连接追踪,iptables 可以对所追踪的连接的数据包进行决策。连接追踪系统为 iptables 带来它所需要的 状态化 的操作。
数据包进入协议栈不久就会应用连接追踪,先对数据包应用 raw 表格中的链,进行一些基本的健康检查,然后才能将其与某个连接关联到一起。
追踪系统会检查每个数据包,将其与已知的连接相比对。需要时,它会更新其仓库中连接的状态,并向系统中增加新的连接。raw 链中被标记了 NOTRACK 目标的数据包不会被追踪。
内核版本 2.6.22 之前使用的是 ip_conntrack 模块,仅支持 IPv4,在后续版本中被移除。从 2.16.15 版本起,开始使用 nf_conntrack 进行追踪,同时支持 IPv4 和 IPv6。
连接追踪引擎
连接追踪引擎使用的是 netfilter 提供的钩子,这些钩子也同样为 iptables 所用。它们被置于协议栈的特殊决策点上,以实现对数据包的检测、修改。
除 FORWARD 以外的其它链都会被追踪。PREROUTING 居于路由决策之前的位置,所有的传入数据包都会遍历这个钩子。连接追踪借此进行初始的查询,它提取数据包的三层、四层连接信息(IP 地址、端口号),检查该数据流的元组是否已存在散列表中。元组中包含两端的 IP 地址及四层信息,通常是端口号。
类似的钩子在 OUTPUT 链上也有,应用于本机生成或回复的数据包。
如果在散列表中没找到传入的连接,四层进行协议追踪,如 TCP 追踪,以判断该数据包是否在创建一个新的连接。
连接追踪的数据结构
连接
netfilter 使用连接这个词,即使对于非连接协议的数据流也是如此。
元组
Tuple
连接追踪模块最重要的数据结构是 nf_conntrack_tuple,该元组结构用来表示一个单向的数据流,使用 IP 地址和传输层信息(如协议、端口号)来区分。双向的数据流则需要两个,每方向用一个元组。
元组结构仅仅是一个数据包的转换,并不是描述一条完整的连接状态,内核中,描述一个包的连接状态,使用的是 ip_conntrack 结构。
连接记录
在 Linux 内核中,连接记录由 ip_conntrack 结构表示,其结构如下图所示。ip_conntrack 连接记录存放在堆里面。
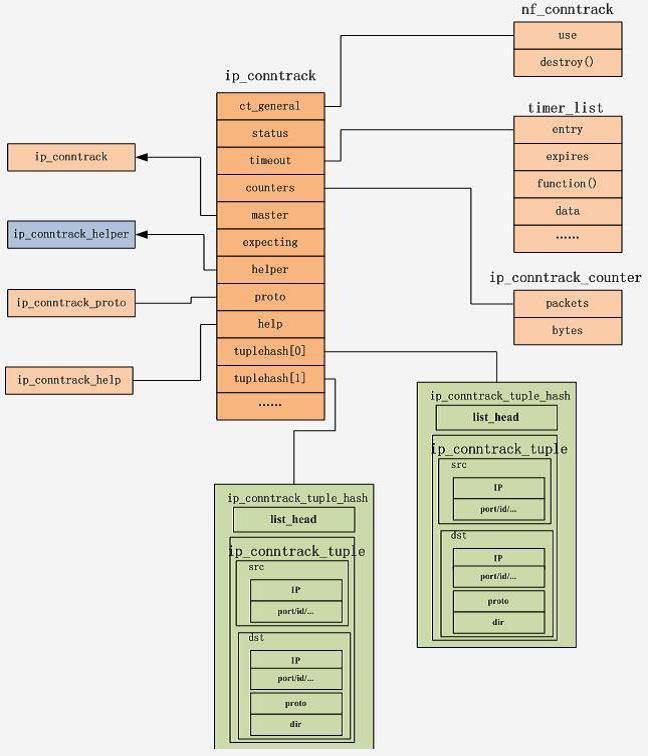
ct_general
一个 nf_conntrack 类型的结构,保存连接记录被公开引用的次数。
counters
一个指向连接超时的函数指针,超时未使用该连接,将调用该指针所指向的函数。
helper
如果针对某种协议的连接追踪需要扩展模块的辅助,则在连接记录中会有一指向 ip_conntrack_helper 结构体的指针。
tuplehash
tuplehash 是一个 ip_conntrack_tuple_hash 类型的数组,该结构描述链表中的 节点,这个数组包含 ogriginal 和 replay 两个成员,即 tuplehash[IP_CT_DIR_ORIGINAL] 和 tuplehash[IP_CT_DIR_REPLY]。
当一个数据包进入连接追踪模块时,先根据其套接字对转换成一个 original 数组,赋值给 tuplehash[IP_CT_DIR_ORIGINAL],然后对该数据包取反,计算出应答的元组,赋值给 tuplehash[IP_CT_DIR_REPLY],这样,一条完整的连接就被记录下来了。
所有连接记录的 ip_conntrack_tuple_hash 以散列形式保存在连接追踪表中。
该结构有两个成员,list 成员用于组织链表。多元组则用于描述具体的数据包。
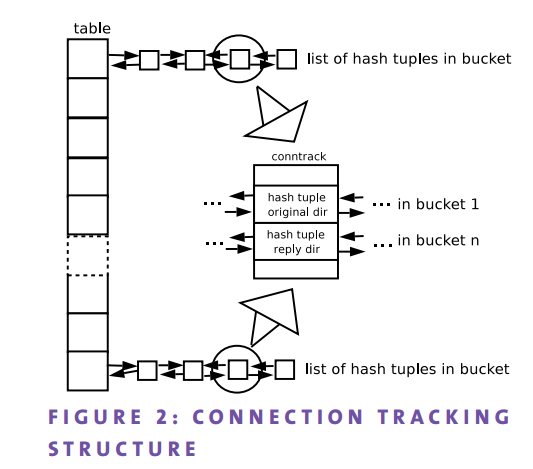
连接追踪表
散列表:Hash Table
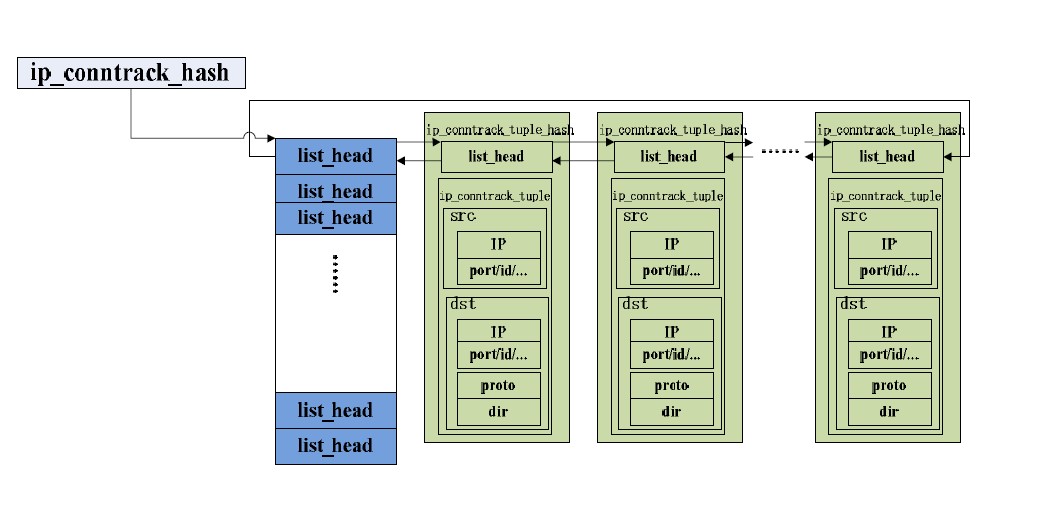
连接追踪表是记录所有连接记录的散列表,用全局指针 ip_conntrack_hash 指针来描述。连接追踪表实际是一个以散列值排列的双向链表数组,链表中的元素即为连接记录所包含的 ip_conntrack_tuple_hash 结构。
netfilter 是如何生成连接记录条目的呢?每一个数据,都有源地址与目标地址,生成条目是指对每一个这样的连接的产生、传输及终止进行追踪记录。由所有条目组成的表,即称为连接追踪表。
连接追踪表是一个用于记录所有数据包连接信息的散列表,其实连接追踪表就是一个以数据包的 hash 值组成的一个双向循环链表数组。
连接追踪引擎使用 散列表 来保存追踪的元组,以实现高效的查询性能。每个连接会添加两次,一次代表正向,一次代表反向(反序添加),这就是为 NAT 服务的。
一个元组代表一个连接的单向信息,包括源IP、目的IP、以及传输层的协议信息。这样的一个元组嵌入到一个散列元组中。双向的元组散列表被嵌入 nf_conn 结构。
通常每个散列表条目包含如下内容:
udp 17 170 src=192.168.1.2 dst=192.168.1.5 sport=137 dport=1025 src=192.168.1.5 dst=192.168.1.2 sport=1025 dport=137 [ASSURED] use=1
^^^ original direction ^^^ reply direction
可以看到,每个条目中同时包含两个方向的连接信息。
查看散列表中的所有条目:
$ sudo cat /proc/net/nf_conntrack
散列表条目总量上限
即最大追踪连接数。
在追踪连接中,一个会话即是一个连接追踪的条目。net.netfilter.nf_conntrack_max 这个参数代表 netfilter 在内核内存中能够处理的最大并发会话数,也就是 最多同时保存多少个追踪条目。
默认值为 nf_conntrack_buckets * 4。
根据这篇 08 年的 wiki,该参数默认值的确定方法为:
CONNTRACK_MAX = RAMSIZE (in bytes) / 16384 / (ARCH / 32)
- 其中
ARCH为 CPU 架构,值为 32 或 64。 - 即:32 位系统使用内存的 1/16384,64 位系统再减半。
- 对于 64 位 8G 内存的机器:
(8 * 1024^3) / 16384 / (64 / 32) = 262144
散列表大小
追踪表的大小由 net.netfilter.nf_conntrack_buckets 表示,即该 散列表的 bucket 数量。
查看当前追踪表大小 nf_conntrack_buckets:
$ sysctl net.netfilter.nf_conntrack_buckets
net.netfilter.nf_conntrack_buckets = 8192
在追踪表中记录的每个条目称为一个 bucket,因此 nf_conntrack_buckets 所代表的追踪表的大小,是指当前追踪表最多可容纳多少 条 记录,即多少个 buckets。
如果在加载模块时没有指定参数,追踪表默认大小为 系统内存大小/16384,但不会小于 32 条,也不会大于 16384 条。对于内存大于 4G 的系统,会设置为 65536 条。
nf_conntrack_buckets 默认值的计算方法:
HASHSIZE = CONNTRACK_MAX / 4
# 比较早的版本是除以 8
# 这里的 4 或 8 就是每个桶里的链表最大长度
对于 64 位 8G 内存的机器:262144 / 4 = 65536
散列表条目
参数 net.netfilter.nf_conntrack_count 用来表示散列表中 当前已产生条目的数量,它代表了当前激活的连接数。
负载系数
Load Factor = nf_conntrack_count / nf_conntrack_buckets
即: 当前条目数量 / 桶的总数
通过负载系数,可以了解当前散列表中桶的使用比例,该系数越大,空桶越少。
当负载系数约为 2/3 时,即约 0.67 左右,散列表中大部分的桶都被占用,hash 冲突的概率会增大,时间复杂度从 O(1) 退化为读链表的 O(n),建议及时为散列表扩容。
追踪表的自动清理
该模块是通过设置一些超时参数,然后在特定时刻开始倒计时,结束时删除条目来实现追踪表的自动清理的。
sudo sysctl -a | grep conntrack | grep timeout
net.netfilter.nf_conntrack_events_retry_timeout = 15
net.netfilter.nf_conntrack_generic_timeout = 600
net.netfilter.nf_conntrack_icmp_timeout = 30
net.netfilter.nf_conntrack_tcp_timeout_close = 10
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_established = 432000
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_last_ack = 30
net.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300
net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60
net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_unacknowledged = 300
net.netfilter.nf_conntrack_udp_timeout = 30
net.netfilter.nf_conntrack_udp_timeout_stream = 180
超时参数的值代表保存 conntrack 记录的秒数,从某个连接收到的最后一个包后,开始超时倒计时,倒数到 0 就会清除记录,倒计时期间如果又收到数据包,倒数会被重置。
小结
-
整个散列表用 ip_conntrack_hash 指针数组来描述,它包含了 nf_conntrack_buckets 个元素,用户态可以在模块插入时传递,默认是根据内存大小计算出来的
-
整个连接追踪表的大小使用全局变量 nf_conntrack_max 描述,与散列表的关系是
nf_conntrack_max = 8 * nf_conntrack_buckets
-
散列表中链表的每一个节点是一个 ip_conntrack_tuple_hash 结构,它有两个成员,一个是 list,一个是 tuple;
-
Netfilter 将每一个数据包转换成 tuple,再根据 tuple 计算出 hash 值,这样,就可以使用 ip_conntrack_hash[hash_id] 找到散列表中链表的入口,并组织链表;
-
找到散列表中链表入口后,如果链表中不存在此 tuple,则是一个新连接,就把 tuple 插入到链表的合适位置;
-
两个节点 tuple[ORIGINAL] 和 tuple[REPLY],虽然是分开的,在两个链表当中,但是如前所述,它们同时又被封装在 ip_conntrack 结构的 tuplehash 数组中;
-
链表的组织采用的是双向链表;
连接追踪的状态
被追踪的连接其状态有以下几种:
NEW
如果收到的数据包与现有的连接均无关联,但做为第一个数据包,它不是无效的,会使用 NEW 标签向系统添加一个新的连接。无论是连接感知型协议如 TCP,还是非连接协议如 UDP,都会如此。
ESTABLISHED
当某个连接收到对端的一个有效的应答时,其状态由 NEW 变为 ESTABLISHED。对于 TCP 连接来说,意味着 SYN/ACK,对于 UDP 和 ICMP 流量来说,意味着一个应答,其中源与目标应该被互换了。
RELATED
如果数据包不属于现有的连接,但与系统中的某个连接有关联,其状态为 RELATED。这种有可能是一个辅助连接,例如 FTP 的数据传输连接,或其它协议尝试连接时收到的 ICMP 应答。
INVALID
如果数据包与现有连接无关,而且也不属于新连接,如果数据包无法被识别,或如果数据包无法路由,则标记为 INVALID。
UNTRACKED
如果在 raw 表链中已经被指定绕过追踪,数据包就可以标记为 UNTRACKED。
SNAT
如果源地址被 NAT 操作修改,则数据包为这种虚拟状态 SNAT。使用该状态是为了在应答数据包中,追踪系统会记得把源地址再改回来。
DNAT
如果目标地址被 NAT 操作修改,则数据包为这种虚拟状态 DNAT。使用该状态是为了在应答数据包中,追踪系统会记得把目标地址再改回来。
有了这些状态,就可以在连接的生存周期内制定针对特定点的规则。这样才能生成更加细致、安全的规则。
追踪表被填满
本小节内容转自 Haunted Hovel,感谢原作者。
连接记录会在连接追踪表里保留一段时间,如果超时后该连接不再收发包,这些记录会被自动删除。
但如果服务器非常繁忙,产生新连接的速度远高于释放旧连接的速度,很容易就把连接追踪表塞满。此时,新连接的数据包会被 丢弃,外部无法正常连接到服务器。
症状
服务器负载正常,但请求大量超时,服务器或应用访问日志看不到相关的请求记录。
在 dmesg 或 /var/log/messages 看到大量以下记录:
kernel: nf_conntrack: table full, dropping packet.
原因
服务器访问量大,内核 netfilter 模块 conntrack 相关参数配置不合理,导致 IP 包被丢掉,连接无法建立。
连接记录会在散列表里保留一段时间,具体多久根据协议和状态有所不同,直到超时都没有收发包就会清除记录。如果服务器比较繁忙,新连接进来的速度远高于释放的速度,把散列表塞满了,新连接的数据包就会被丢掉。此时 netfilter 变成了一个黑洞,这些都发生在网络层,应用程序对此无能为力。
如果有人 DDoS 攻击的话情况更糟,无论是空连接攻击,还是简单地用短连接发大量请求都能轻易塞满散列表。或者更隐蔽点,研究了计算 conntrack hash 值的算法后,构造很多 hash 一致的不同五元组的数据包,让大量记录堆在同一个 bucket 里,使得遍历超长的冲突链表的开销大得难以接受。在当前的内核 conntrack 模块实现中,这是无法避免的(除非关掉不用),因为所有鸡蛋都在一个篮子里面。
诊断
查看所有 netfilter 相关内核参数:
sudo sysctl -a | grep conntrack
单独查看 超时参数:
sudo sysctl -a | grep conntrack | grep timeout
散列表设置
查看 散列表大小:
sudo sysctl net.netfilter.nf_conntrack_buckets
查看 最大追踪连接数。进来的连接数超过这个值时,新连接的包会被丢弃。
sudo sysctl net.netfilter.nf_conntrack_max
比较现代的系统(Ubuntu 16+, CentOS 7+)里,64 位,8G 内存的机器,max 通常默认为 262144,bucket 为 65536。随着内存大小翻倍这 2 个值也翻倍。
【注意】云服务厂商可能有不同的默认设置:
- AWS 8G 以上这 2 个值似乎不再增加,64G 内存的机器和 8G 内存的机器一样。
- 阿里云目前(2018年)CentOS 7+ 的机器上似乎还在用 07 年 CentOS 5 时代的默认配置:max 为 65536,bucket 为 16384。因此如果生产环境用阿里云服务器又没人了解这块的话,陷阱会来得特别早。
查看 netfilter 模块 加载时的默认设置:
sudo dmesg | grep conntrack
# 找类似这样的记录:
# nf_conntrack version 0.5.0 (65536 buckets, 262144 max)
散列表使用情况
查看散列表中当前条目数量:
sudo sysctl net.netfilter.nf_conntrack_count
# 只读
# 这个值跟 sudo conntrack -L 或 /proc/net/nf_conntrack (如果有这文件)里的条目数一致
查明当前条目数量以后,计算负载系数,以了解当前负载状况。
查看追踪连接记录:
sudo tail -n 50 /proc/net/nf_conntrack
# 输出例:
# ipv4 2 tcp 6 431999 ESTABLISHED src=10.0.13.67 dst=10.0.13.109 sport=63473 dport=22 src=10.0.13.109 dst=10.0.13.67 sport=22 dport=63473 [ASSURED] mark=0 secctx=system_u:object_r:unlabeled_t:s0 zone=0 use=2
# 记录格式:
# 网络层协议名、网络层协议编号、传输层协议名、传输层协议编号、记录失效前剩余秒数、连接状态(不是所有协议都有)
# 之后都是 key=value 或 flag 格式,1 行里最多 2 个同名 key(如 src 和 dst),第 1 次出现的来自请求,第 2 次出现的来自响应
# flag:
# [ASSURED] 请求和响应都有流量
# [UNREPLIED] 没收到响应,散列表满的时候这些连接先扔掉
四层协议类型和连接数:
sudo cat /proc/net/nf_conntrack | awk '{sum[$3]++} END {for(i in sum) print i, sum[i]}'
TCP 连接各状态对应的条数:
sudo cat /proc/net/nf_conntrack | awk '/^.*tcp.*$/ {sum[$6]++} END {for(i in sum) print i, sum[i]}'
三层协议类型和连接数:
sudo cat /proc/net/nf_conntrack | awk '{sum[$1]++} END {for(i in sum) print i, sum[i]}'
连接数最多的 10 个 IP 地址:
sudo cat /proc/net/nf_conntrack | awk '{print $7}' | cut -d "=" -f 2 | sort | uniq -c | sort -nr | head -n 10
解决
关闭使用 NAT 的程序
最常见的是防火墙,其次常见的可能是 docker。依赖 netfilter 模块的服务被关掉之后,通常 sudo sysctl -a | grep conntrack 就找不到相关的参数了。
关闭防火墙
对不直接暴露在公网,也不使用 NAT 转发的服务器来说,关闭 Linux 防火墙是最简单的办法,还避免了防火墙/netfilter 成为网络瓶颈。使用公有云的话可以用厂商提供的安全服务,通常是独立于你租的云服务器的,不消耗资源,比自己用系统防火墙设一大堆规则好得多。
sudo systemctl stop firewalld
sudo systemctl disable firewalld
sudo systemctl stop iptables
sudo systemctl disable iptables
关闭 Dockerd
系统是最小安装的话应该不会自带。如果发现系统里有 docker 的网卡在,又确定没有地方用到 docker 的话就关掉:
sudo systemctl stop docker
sudo systemctl disable docker
如果 conntrack 相关参数还没消失,看看模块是不是还在:
lsmod | egrep "Module|ip_table|iptable|ip6|ipt|nat|conntrack"
# 有可能会匹配到不相关的,最好对照一下这里
find /lib/modules/$(uname -r) -type f -name '*.ko*' | grep netfilter
# 查看模块详细信息
modinfo <module>
禁用模块:
sudo modprobe [-f] -r <module> [<module2> ...]
# 或:
sudo rmmod [-f] <module>
# 未使用(Used by 栏为 0)的模块才能禁用。
# 如果 Used by 不为 0,先禁用后面列出的模块。
# 如果后面没模块名,就是被进程使用。
# 没有简单的方法能查到调用这些模块的都是什么进程,基本靠猜。
# 查看启动信息,看有没有有用的线索(多半没有)
dmesg | egrep "ip_table|netfilter|conn"
调整内核参数
如果调用 netfilter 的进程无法终止,或查不出是什么进程在用,就要靠调整参数来尽量推迟出问题的时间。
主要设置项:
- 散列表扩容:
nf_conntrack_buckets、nf_conntrack_max - 让散列表条目尽快释放:超时相关参数
散列表扩容的影响
为散列表扩容以后,除了内存使用增加以外,对于 32 位系统,还要考虑内核态的地址空间是否够用。
netfilter 的散列表存储在内核态的内存空间,这部分内存不能 swap。给 netfilter 分配太多地址空间可能会导致其他内核进程不够分配,因此要为其分配尽量合理的地址空间,而散列表所占用内存空间的大小完全取决于 CONNTRACK_MAX 和 HASHSIZE。因此,在调整这两个参数之前,有必要进行仔细的计算,以确保不会占用过多的内存空间。
操作系统为了兼容 32 位,默认值往往比较保守。32 位系统的虚拟地址空间最多 4G,其中内核态最多 1G,通常能用的只有前 896M。1 条追踪记录约占 300 字节,如果 nf_conntrack_max 默认值为 65535 条,约占 20MB 内存空间。
而 64 位系统的虚拟地址空间有 256TB,内核态能用 一半,无需精打细算,只需要关心物理内存的使用情况。
- 计算 conntrack 的内存占用量的方法:
size_of_mem_used_by_conntrack (in bytes) = CONNTRACK_MAX * sizeof(struct ip_conntrack) + HASHSIZE * sizeof(struct list_head)
其中:
sizeof(struct ip_conntrack) :在不同架构、内核版本、编译选项下不一样。这里按 352 字节算。
sizeof(struct list_head) = 2 * size_of_a_pointer : 32 位系统的指针大小是 4 字节,64 位是 8 字节
- 范例一:64 位系统,8G 内存的主机,按默认
CONNTRACK_MAX为 262144,HASHSIZE为 65536
其散列表内存占用量为:
262144 * 352 + 65536 * 8 = 92798976 = 88.5 MB
- 范例二:主机内存足够大,
CONNTRACK_MAX为 1048576,HASHSIZE为 262144
其散列表内存占用量为:
1048576 * 352 + 262144 * 8 = 371195904 = 354 MB
压力测试方法:压测工具不使用 keep-alive 来发送请求,调大 nf_conntrack_tcp_timeout_time_wait,单机跑一段时间就能填满散列表。观察响应时间的变化和服务器内存的使用情况。
扩容散列表
除了有关联的参数,尽量一次只改一处,记录下默认值和上次改的值,如果效果不明显甚至更差则立即还原。修改完要多观察一段时间,确保不会影响业务。
- 修改桶的数量
net.netfilter.nf_conntrack_buckets 参数是只读的,不能直接改,需要修改模块的设置:
# 改为 262144
echo 262144 | sudo tee /sys/module/nf_conntrack/parameters/hashsize
# 再查看,此时 bucket 已经变成刚才设置的值
sudo sysctl net.netfilter.nf_conntrack_buckets
- 修改条目总数上限
net.netfilter.nf_conntrack_max 参考默认值,设为桶的 4 倍:
sudo sysctl net.netfilter.nf_conntrack_max=1048576
# 改完可以看到 net.netfilter.nf_conntrack_max 和 net.nf_conntrack_max 都变了
调整超时参数
如果你的程序需要读取 conntrack 记录,或者服务器设了复杂的 iptables 规则(同样需要读取 conntrack 记录),超时时间的设置需要 非常谨慎:
如果 conntrack 记录对你不重要,用之前的命令查一下哪种协议哪种状态的连接最多,尝试把对应的超时参数调小。占比很少或根本用不到的可以不管。
例如 Nginx 服务器上可能会看到 90% 以上的记录都是 TIME_WAIT 状态(Nginx 连后端服务默认用短连接)。
- 对于通外网的服务器,考虑调整以下参数,减少 DDoS 的危害:
net.netfilter.nf_conntrack_tcp_timeout_established:默认 432000 (5天)
这个值对应的场景是 “双方建立了连接后一直不发包,直到 5 天后才发”
但默认 keep-alive 超时时间只有 2 小时 11 分(net.ipv4.tcp_keepalive_time + net.ipv4.tcp_keepalive_intvl * net.ipv4.tcp_keepalive_probes),由于超时关 socket 不发包,conntrack 无法根据包头的标识知道状态的变化,记录会一直处于 ESTABLISHED 状态,直到 5 天后倒计时结束才删掉。
空连接攻击的最佳目标。攻击者把 IP 包头的源地址改成随机 IP,握完手就关 socket,用一台机发请求就能把你的散列表填满。
net.netfilter.nf_conntrack_tcp_timeout_syn_recv:默认 60
类似,故意不发握手的 ACK 即可。但这个超时时间没那么夸张,系统也有 syn cookie 机制来缓解 syn flood 攻击。
- 其他值得注意的参数:
net.netfilter.nf_conntrack_tcp_timeout_syn_sent:默认 120
你的程序的 connect timeout 有这么长吗?
net.netfilter.nf_conntrack_tcp_timeout_fin_wait:默认 120
net.ipv4.tcp_fin_timeout 默认 60 秒,通常还会参考 BSD 和 macOS 设成更小的值。这里往往也没必要这么大。
net.netfilter.nf_conntrack_icmp_timeout:默认 30
哪里的 ping 会等 30 秒才超时?
net.netfilter.nf_conntrack_tcp_timeout_time_wait:默认 120
Linux 里的 MSL 写死 60 秒(而不是 TCP 标准里拍脑袋的 120 秒),TIME_WAIT 要等 2MSL,这里 120 算是个合理的值。
但现在默认有 PAWS(net.ipv4.tcp_timestamps),不会出现标准制定时担心的迷途报文回来碰巧污染了序列号相同的新连接的数据的情况,互联网公司基本都开 net.ipv4.tcp_tw_reuse,既然半连接都不留这么久,记录似乎也不需要留这么久。
net.netfilter.nf_conntrack_tcp_timeout_close_wait:默认 60
CLOSE_WAIT 状态是让被动关闭方把该传的数据传完。如果程序写得不好,这里抛了未捕捉的异常,也许就走不到发 FIN 那步了,一直停在这里。
net.netfilter.nf_conntrack_tcp_timeout_last_ack:默认 30
被动关闭方发 FIN 后如果一直收不到对面的 ACK 或 RST,会不断重发,直到超时才 CLOSE。net.ipv4.tcp_retries2 的默认值是 15,最多要等 924.6 秒……不过一般都会调小这个值。
- 修改超时参数范例:
先直接在终端修改,以测试效果:
sudo sysctl net.netfilter.nf_conntrack_icmp_timeout=10
sudo sysctl net.netfilter.nf_conntrack_tcp_timeout_syn_recv=5
sudo sysctl net.netfilter.nf_conntrack_tcp_timeout_syn_sent=5
sudo sysctl net.netfilter.nf_conntrack_tcp_timeout_established=600
sudo sysctl net.netfilter.nf_conntrack_tcp_timeout_fin_wait=10
sudo sysctl net.netfilter.nf_conntrack_tcp_timeout_time_wait=10
sudo sysctl net.netfilter.nf_conntrack_tcp_timeout_close_wait=10
sudo sysctl net.netfilter.nf_conntrack_tcp_timeout_last_ack=10
用 sysctl [-w] 或 echo xxx > /pro/sys/net/netfilter/XXX 做的修改在重启后会失效。
如果测试没有问题,在 /etc/sysctl.d/ 目录中新建配置文件,如 90-conntrack.conf (CentOS 6 等旧系统编辑 /etc/sysctl.conf),系统启动时会加载里面的设置:
# 格式:<参数>=<值>,等号两边可以空格,支持 # 注释
net.netfilter.nf_conntrack_max=1048576
net.netfilter.nf_conntrack_icmp_timeout=10
net.netfilter.nf_conntrack_tcp_timeout_syn_recv=5
net.netfilter.nf_conntrack_tcp_timeout_syn_sent=5
net.netfilter.nf_conntrack_tcp_timeout_established=600
net.netfilter.nf_conntrack_tcp_timeout_fin_wait=10
net.netfilter.nf_conntrack_tcp_timeout_time_wait=10
net.netfilter.nf_conntrack_tcp_timeout_close_wait=10
net.netfilter.nf_conntrack_tcp_timeout_last_ack=10
修改配置文件以后,立即应用新的配置:
sudo sysctl -p /etc/sysctl.d/90-conntrack.conf
# 不传文件路径默认加载 /etc/sysctl.conf
减少追踪连接数
以 iptables 为例,查看所有规则:
sudo iptables-save
这个必须插在第 1 条,凡是不跟踪的肯定是你想放行的:
sudo iptables -I INPUT 1 -m state --state UNTRACKED -j ACCEPT
# 设置成不跟踪的连接无法拿到状态,包含状态(-m state --state)的规则统统失效。
# iptables 处理规则的顺序是从上到下,如果这条加的位置不对,可能导致请求无法通过防火墙。
不跟踪本地连接:
sudo iptables -t raw -A PREROUTING -i lo -j NOTRACK
sudo iptables -t raw -A OUTPUT -o lo -j NOTRACK
# 假如 Nginx 和应用部署在同一台机子上,增加这规则的收益极为明显。
# Nginx 连各种 upstream 使得连接数起码翻了倍,不跟踪本地连接一下干掉一大半。
-t raw 会加载 iptable_raw 模块(kernel 2.6+ 都有) 。
raw 表基本就干一件事,通过 -j NOTRACK 给不需要被连接跟踪的包打标记(UNTRACKED 状态),告诉 nf_conntrack 不要跟踪连接。
raw 的优先级大于 filter,mangle,nat,包含 PREROUTING(针对进入本机的包) 和 OUTPUT(针对从本机出去的包) 链。
不跟踪某些端口的连接:
sudo iptables -t raw -A PREROUTING -p tcp -m multiport --dports 80,443 -j NOTRACK
sudo iptables -t raw -A OUTPUT -p tcp -m multiport --sports 80,443 -j NOTRACK
配完防火墙规则记得留意后台服务还能不能连得上、响应时间有没有异常、某些 TCP 状态有没有异常增加……
确定没问题就保存规则(否则重启服务后失效):
# CentOS 6 等使用 SystemV init 的旧系统:
sudo service iptables save
# 其实就是把 iptables-save 的内容存到 /etc/sysconfig/iptables
iptables 规则
规则的构成
规则被置于链中,链置于表中。每个链被调用时,会用其中的规则依次对数据包进行检查。
每条规则都有一个 匹配 组件和一个 动作 组件。
匹配
规则中的匹配部分,用于指定数据包必须满足的条件,以便最终执行相关的动作(或目标)。
匹配的系统非常灵活,可以用系统中可用的 iptables 扩展来实施更强大的匹配。
构建规则时可以使用协议类型、目标地址、源地址、目标端口、源端口、目标网络、源网络、输入接口、输出接口、包头、连接状态等。可以把多个要素组合起来,创建相当复杂的规则集,用来区分不同的流量。
目标
目标,是数据包满足规则中匹配的条件时,所触发的动作。
目标主要分为两类:
中止型目标
中止型目标,它所进行的操作会中止对规则链的评估,将控制返还给 netfilter 钩子。根据返回值,钩子丢弃或允许数据包进入下一步流程。
非中止型目标
非中止型目标完成操作以后,会继续对规则链的评估。
创建规则的语法
iptables [-t table] command [match] [target/jump]
[-t table] :要想使用非标准表格,可以使用该选项。然而,一般都无需显式声明用哪个表,因为 iptables 默认使用 filter 表来执行部署所有的命令。
command :记住,命令放在最前面。我们用命令来告诉 iptables 做什么。例如在某位置插入一条规则,或加到链的末尾,或删除一条规则。
[match] :此处详细描述数据包的特点,是什么使其与众不同。比如在此可以描述数据包的源地址、入站网络接口、目标地址、端口、协议等。
[target/jump] :如果所有条件均匹配,就可以告诉内核做什么了。比如,告诉内核把数据包发给同表中另一条自定义链,或是不加任何处理丢弃数据包,或向发送方回复特定的消息等。
表格
iptables -t nat
有效值为 raw,mangle,nat,filter 这四张内置表格。如果不显式声明表格,默认使用 filter。
命令
语句中的命令用于告诉 iptables 要如何操作后面的规则,如在表中添加、删除规则。
-A
--append 向链尾 追加规则。
例: iptables -A INPUT
-D
--delete
删除 链中的规则。
有两种方式:
- 键入整条规则来匹配:
例: iptables -D INPUT --dport 80 -j DROP
必须把整条规则一字不差地打出来。
- 使用规则编号来匹配:
iptables -D INPUT 1
规则编号从 1 开始。
-R
--replace
替换 指定行的规则。
例: iptables -R INPUT 1 -s 192.168.0.1 -j DROP
-I
--insert
在链的某处 插入 一条规则。
例: iptables -I INPUT 1 --dport 80 -j ACCEPT
-F
--flush
清除 指定链中的所有规则:
例: iptables -F INPUT
如果不使用任何选项,则清除特定表中所有链中的所有规则:
iptables -F
-Z
--zero
将指定链中所有的 计数器清零。
例: iptables -Z INPUT
-N
--new-chain
告诉内核在特定表格中 创建 一个指定名称的 新链。
例: iptables -t nat -N BT
在 nat 表中创建一个名为 BT 的链。
-X
--delete-chain
从表中 删除某链。删除之前,必须确认没有任何规则引用该链。
例: iptables -X BT
如果不使用任何选项,会删除所有非内置链。
iptables -X
-P
--policy
为某链设定默认的目标或策略。可接受的取值为 DROP 和 ACCEPT。
所有不匹配任何规则的数据包最后会被强制使用该链的默认策略。
-E
--rename-chain
重命名 某链。
例: iptables -E BT BTdownload
把 BT 重命名为 BTdownload。
选项
-v
--verbose
显示更详细的信息。
通常与 -L 配合使用,以便额外显示接口地址、规则选项、TOS 掩码、计数器等。
如果 -v 与 -A、-I、-D、-R 配合使用,会显示额外的信息,以告知用户规则是如何被解释的,是否正确插入了等等。
例: iptables -L -v
-n
--numeric
尽量以数字格式输出。不显示主机名,显示 IP 地址与端口号。
只能与 -L 配合使用。
例: iptables -L -n
--line-numbers
与 -L 配合使用,显示行号。
每条规则前面都会显示行号,便于使用行号对特定规则进行操作。
例: iptables -L --line-numbers
匹配
关于匹配的内容实在是过于复杂,仅列出常用的几个。
通用匹配
使用通用匹配时,无需附加额外的特殊参数。
-p
--protocol
检测特定的协议。常用的协议为 TCP、UDP、ICMP。
- 协议也可取自
/etc/protocols中的协议,还可以使用其中的 数字编号 来代表,如 TCP 为 6,UDP 为 17。 - 取值也可以用
ALL,代表仅匹配 TCP、UDP、ICMP。 - 如果取值为 0,则代表匹配所有协议。也是该选项的默认值,即不使用
-p则代表匹配所有协议。 - 取值时前面加
!可用来取反。如-p !tcp代表所有非 TCP 的协议。
例: iptables -A INPUT -p tcp
-s
--source
用于匹配数据包的 源 IP 地址。
例: iptables -A INPUT -s 192.168.1.1
- 可匹配单一地址:
-s 192.168.1.1 - 可匹配网段:
-s 192.168.1.0/24或-s 192.168.1.0/255.255.255.0 - 使用
!可取反:-s ! 192.168.0.0/24
默认为匹配所有 IP 地址。
-d
--destination
用于匹配数据包的 目标 IP 地址。用法同 -s
例: iptables -A INPUT -d 192.168.1.1
-i
--in-interface
用于匹配数据包 入站 的网络 接口。
例: iptables -A INPUT -i eth0
只能用在 INPUT、FOWWARD、PREROUTING 链中。
如果没有指定接口,该匹配的默认行为是假设为其指定的字符串为 +。该值会匹配由字母和数字组成的字符串。实际上等于告诉内核匹配所有的数据包,不管它是从哪个接口来的。
-i eth+ 匹配所有的以太网设备。
-i ! eth0 匹配所有非 eth0 的接口。
-o
--out-interface
用于匹配数据包 出站 的网络 接口。
例: iptables -A FORWARD -o eth0
只能用在 OUTPUT、FORWARD、POSTROUTING 链中。
其它用法同 -i。
-f
--fragment
该匹配专门用来匹配分片数据包的第二个和第三个片。
例: iptables -A INPUT -f
使用该选项的原因是:当数据包发生分片时,无法区分片的源端口和目标端口,以及 ICMP 类型。而且分片数据包经常被用来进行网络攻击。匹配的切片不会再被其它规则匹配。
虽然也可以使用 ! 来取反,但比较特殊的是,必须放在选项之前,即 ! -f。取反之后的含义是,只匹配第一个片。也匹配所有没有被分片的数据包。
内核中有更好的反分片选项。如果使用了连接追踪,就不会看到任何分片的数据包,因为在它们遇到任何链或表之前就已经被处理了。
隐式匹配
隐式匹配是指默认就自动匹配的内容。也就是说即使在语句中没有,默认也是匹配的。
TCP 匹配
这些匹配都是针对特定协议的,只适用于 TCP 流量。
要想使用 TCP 匹配,必须在语句中先使用 -p tcp。
--sport
--source-port
匹配数据包的 源端口。可以指定端口号,也可以使用 /etc/services 中的服务名称来指定。
例 :iptables -A INPUT -p tcp --sport 22
如果不指定,则默认匹配所有源端口号。这就是隐式匹配。
如果直接指定端口号,规则加载起来会稍微快一些,因为 iptables 不用再去解析服务名称。规则越多,越应该使用端口号,以减少解析服务名称所浪费的时间。
可以匹配一定范围的端口号:
iptables -A INPUT -p tcp -sport 22:80
使用 ! 取反:
iptables -A INPUT -p tcp ! 22
iptables -A INPUT -p tcp ! 22:80
--dport
--destination-port
匹配数据包的 目标端口。
例 :iptables -A INPUT -p udp --dport 53
用法同 --sport。
UDP 匹配
--sport
--source-port
匹配数据包的 源端口。
--dport
--destination-port
匹配数据包的 目标端口。
例 :iptables -A INPUT -p udp --dport 53
显式匹配
显式匹配必须使用 -m 或 --match 选项来显式指定,否则默认不会匹配。这部分的内容最为丰富,根据实际需要参考使用指南。
IP 范围匹配
-m iprange --src-range
-m iprange --dst-range
用于匹配 IP 地址范围。--src-range 指定源地址范围,--dst-range 指定目标地址范围。
例:
iptables -A INPUT -p tcp -m iprange --src-range 192.168.1.13-192.168.2.19
取反:
iptables -A INPUT -p tcp -m iprange ! --dst-range 192.168.1.13-192.168.2.19
长度匹配
-m length --length
匹配数据包的长度。
例 :
iptables -A INPUT -p tcp -m length --length 1400
iptables -A INPUT -p tcp -m length --length 1400:1500
iptables -A INPUT -p tcp -m length ! --length 1400:1500
限制匹配
-m limit --limit --limit-burst
匹配规则的数据包被 iptables 放行,相当于给它签发了一个通行证,而限制匹配就是用来防止通行证发行过快,以抵御 高频访问 所带来的危险,如 DOS 攻击。
我们就用通行证来解释限制匹配的工作原理:
许多数据包在游乐园排队准备玩儿一个游戏,比如疯狂老鼠。入口有一个小盒子,用来放门票。盒子在刚开始时是满的,门票数量是一定的。数据包走到入口,从盒子里取一张门票,它被放行,盒子里的门票就少一张。工作人员会旁边监督,只要盒子里的门票不是满的,就会按一定的频率,每次一张地往盒子里放门票,直到放满为止。如果轮到某个数据包发现盒子里只剩下一张票了,它就会决定不玩了,去下一个景点转转。
--limit :补发门票的频率,单位时间内发几张门票。即 单位时间内最多匹配几次。有效的单位时间为 /second、/minute、/hour、/day。默认值为 3/hour。
--limit-burst :门票的初始数量,也是有效门票的上限。即 初始允许连续匹配的数量 数据包每匹配一次,该数字就会减一,直到减到 1 为止。只要该数字发生了变化,系统就会按 --limit 指定的频率往回加一,一直加到其初始值为止。
如果数据包访问频率激增,导致 --limit-burst 的数量迅速被用完,后面的数据包就会认为是不匹配的,直接跳到该条规则的尾部,要么进入该规则的默认策略,要么可能跳转到另一规则。
例 :
iptables -A INPUT -p icmp -m limit --limit 6/m --limit-burst 5 -j ACCEPT
iptables -P INPUT DROP
从另一台主机上 ping 这台主机,情况如下:
- 前四个包的应答都很正常,从第五个包开始,每 10 秒能收到一个正常的应答。
--limit 6/m 的作用 :每分钟允许通过 6 个包,即每 10 秒只能通过一个。
--limit-burst 5 的作用 :设定初始值及匹配上限为 5。因此,前 4 个包可以正常匹配,第 5 个包开始,进入限制状态,每 10 秒才能通过一个包。如果之后的 10 秒钟没有包抵达,则 --limit-burst 加 1,如果一直没有包抵达,加到 5 就停止。重新进入初始状态。
- 假如停止 ping,等待 30 秒后再次开始 ping。
此时,前两个包是正常的,但从第三个开始丢包。因为我们再次开始 ping 的时候,--limit-burst 仅恢复到了 4。
注意:--limit-burst 递减的 极限值是 1,并非是 0。因此,从 1 开始恢复时,在第 32 秒钟,其值应该增加了三次,因此为 1+1+1+1=4 。
限制匹配的用途
- 限制特定包的传入速度
- 限制特定端口传入频率
- 防范
SYN-Flood碎片攻击
Mac 匹配
-m mac --mac-source
即 MAC 地址匹配。
例 :iptables -A INPUT -m mac --mac-source 00:00:00:00:00:01
多端口匹配
-m multiport --source-port / --destination-port / --port
可以同时匹配多个端口。
例 :
iptables -A INPUT -p tcp -m multiport --source-port 22,53,80,110
iptables -A INPUT -p tcp -m multiport --destination-port 22,53,80,110
iptables -A INPUT -p tcp -m multiport --port 22,53,80,110
状态匹配
-m state --state
匹配数据包的状态。
例 :iptables -A INPUT -m state --state RELATED,ESTABLISHED
目标或跳转
数据包完美匹配之后,该对其进行什么操作,通过目标或跳转来定义。
跳转
jump
跳转是指从一个链 跳转到 同一表中的 另一个链。
范例
在 filter 表中创建一个表,名为 tcp_packets:
iptables -N tcp_packets
增加一条跳转到它的规则:
iptables -A INPUT -p tcp -j tcp_packets
于是,数据包会从 INPUT 链跳转到 tcp_packets 链,开始遍历这条链,到达链尾时,数据包会被返回 INPUT 链,从之前跳转的位置继续向下遍历。
如果数据包在跳转到的子链中被接受,即遇到 ACCEPT 目标,它就不会返回主链了。
目标
目标:target
目标只是用来设定对匹配的数据包所要进行的 操作。
我们把执行条规则的目标,也可以称为跳转到某个目标,这样与跳转就在语义上就统一了。
跳转到不同的目标会产生不同的结果:
- 某些目标会导致数据包停止遍历子链及主链,如 DROP 和 ACCEPT。
- 某些目标可能会对数据包进行一些操作,然后数据包可继续遍历其余的规则,如 LOG、ULOG、TOS ,这些目标可以把数据包记录到日志中,可以修改数据包,然后将其传递给同链的其它规则。
- 某些目标可以接受额外的选项,如使用 TOS 的特定值
- 某些目标不接受任何选项
目标也有很多,这里也只简单介绍几个常用的:
ACCEPT
-j ACCEPT
该目标不需要任何其它选项。在数据包完美匹配之后,如果把 ACCEPT 做为其目标进行跳转,该规则即被接受,数据包就不会再继续遍历同表中的当前链以及其它任何链了。
但是,在一个表中被授受的数据包,到了另一个表中仍然可能会遍历别的链,仍然有可能被丢弃。
DNAT
该目标用于进行 DNAT 地址转换。
它会重写匹配数据包的目标 IP 地址,该数据包以及同一数据流中的后续数据包都会被转换,然后路由到正确的设备、主机或网络。
该目标非常有用,例如,在局域网中有一台运行网页服务器的主机,但它没有公网 IP 地址。防火墙可以把所有访问其 HTTP 端口的数据包全部转发给后端的这台服务器。还可以指定一个目标地址网段,由 DNAT 随机决定把每个数据流转发给谁。以此实现 负载均衡。
DNAT 目标只可用于 nat 表中的 PREROUTING 和 OUTPUT 链,以及其子链。包含 DNAT 的链不能被其它链调用,比如 POSTROUTING 链。
例 :
iptables -t nat -A PREROUTING -p tcp -d 15.45.23.67 --dport 80 -j DNAT --to-destination 192.168.1.10
DROP
该目标会把数据包丢弃掉,不再进行任何处理。
被丢弃的数据包会直接被挡在外面,直接死掉了。该行为在某些时候有可能会导致不好的结果,因为它可能会在两端的主机中留下死掉套接字。比较好的解决办法是使用 REJECT 目标,尤其是希望避开端口扫描,以免泄漏太多信息,如过滤的端口号等。
如果数据包在某个子链遇到 DROP 目标,则数据包不会再处理,无论是在主链还是当前子链,还是其它表中。这个数据包被认为彻底死掉了,该目标不会给连接两端发送任何信息。
LOG
该目标是专为保存关于数据包的日志信息而设计的,可以用于规则的调试与除错。
该目标会返回数据包的特定信息,如 IP 头中的大部分信息,以及其它有用的信息。LOG 目标的操作是通过内核的日志功能实现的,通常使用 syslogd。这些信息之后可以用 dmesg 直接读取,或从 syslogd 日志读取,或者用其它程序。
通过该目标对规则进行除错非常方便,可以查看数据包去了哪里,规则应用到了哪些数据包上等。因此,在对自定义的规则不太确定时,可以暂时用 LOG 来代替 DROP 进行测试,以避免错误的语法让用户产生严重的连接故障。
如果在使用扩展日志,可以使用 ULOG 目标,该目标支持直接向 MySQL 数据库记录日志。
如果在命令行看到有讨厌的日志输出,这不是 iptables 或 netfilter 的问题,而是由于 syslogd 配置不正确导致的,通常可以通过修改 /etc/syslog.conf 来解决。同时可能还需要修改 dmesg 的配置,dmesg -n 1 可以避免一般日志显示到终端窗口中。dmesg 的消息级别与 syslogd 的级别是精确匹配的,它只作用于来自内核模块的日志消息。
LOG 目标接受以下选项:
--log-level
告知 iptables 和 syslog 要使用什么级别(优先级)的日志。要想了解日志的各个级别,可以查看 syslog.conf 的帮助文档。
例:iptables -A FORWARD -p tcp -j LOG --log-level debug
日志级别通常有:
- debug
- info
- notice
- warning
- warn
- error
- crit
- alert
- emerg
- panic
通常不建议使用 error、warn、panic。这些级别定义了消息的严重程度。
所有的消息都是通过内核功能实现的。如,在 syslog.conf 中设置 kern.=info /var/log/iptables,然后在 iptables 中把日志级别设定为 info,所有的日志就会保存到 /var/log/iptables 中了。此时,该日志中还会看到同是 info 级别的内核其它部分的日志。
--log-prefix
该选项会给所有的日志消息加一个前缀,这样就容易用 grep 之类的工具快速追踪了。最多可以用 29 个字母,包括空白字符和其它特殊字符。
例:iptables -A INPUT -p tcp -j LOG --log-prefix "INPUT packets"
--log-tcp-sequence
用于在保存日志消息的同时,记录 TCP 序列编号。
注意:如果含有 TCP 序列编号的日志被未授权的用户看到,可能有安全风险。
例:iptables -A INPUT -p tcp -j LOG --log-tcp-sequence
--log-tcp-options
用于记录 TCP 包头中有差异的选项。
例:iptables -A FORWARD -p tcp -j LOG --log-tcp-options
--log-ip-options
用于记录 IP 包头中大部分选项。
例:iptables -A FORWARD -p tcp -j LOG --log-ip-options
MARK
--set-mark
该目标用于为特定的数据包打上 netfilter 特有的标记。只适用于 mangle 表中,其它表中无效。
MARK 的值可用来进行高级的路由,把不同的数据包从不同的路由发送出去,并要求它们使用不同的 qdisc。
MARK 值不是在实际的数据中设置的,而是通过它与内核中的某个值相关联。也就是说,在本机为数据包做的标记,当数据包达到其它主机时,就无效了。
MARK 值只接受整数。
例:
iptables -t mangle -A PREROUTING -p tcp --dport 22 -j MARK --set-mark 2
为特定的数据流打上标签 2,然后在本机进行高级路由操作。
MASQUERADE
--to-ports
该目标与 SNAT 基本相同,但它不需要 --to-source 选项。因为它是专门用于 动态 IP 地址 环境的,如拨号连接或 DHCP 连接。
对某个连接应用该目标,意味着自动获取特定网络接口的 IP 地址。应用该目标的效果是,如果接口被禁用,该连接马上就会被遗忘,在杀掉特定连接时,这是一件好事。如果用的是 SNAT 目标,很可能会遗留下很多以前连接的追踪数据,可能会保留很多天,会占用掉宝贵的连接追踪内存。而在使用拨号连接时,每次可能都会获取到不同的 IP 地址,对于这种情况,就应该 及时清理掉旧的连接追踪数据。
实际上,即使是静态 IP 地址,也可以用 MASQUERADE 目标代替 SNAT,但不太讨巧,因为这会增加额外的开销。
MASQUERADE 只适用于 POSTROUTING 链。
例:
iptables -t nat -A POSTROUTING -p TCP -j MASQUERADE --to-ports 1025
iptables -t nat -A POSTROUTING -p TCP -j MASQUERADE --to-ports 1024-31000
REDIRECT
该目标用于在本机内部进行重定向,把数据包重定向到自己身上,通常是重定向到另一个端口。该目标非常适合做透明代理。
例如,可以把流向 80 端口的数据包重定向到本机的 squid 等 HTTP 代理服务上。
REDIRECT 目标只适用于 nat 表中的 PREROUTING 和 OUTPUT 链,也可用于自定义链中。
例:
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080
REJECT
拒绝接受,与 DROP 基本相同,但它会向对端发送错误消息,以告知数据包被拒绝。
REJECT 目标只适用于 INPUT、FORWARD、OUTPUT 链及其子链。
例:
iptables -A FORWARD -p TCP --dport 22 -j REJECT --reject-with tcp-reset
RETURN
该目标会让当前数据包 停止在当前链中的穿行,如果当前在子链中,则 返回主链 继续遍历;如果当前就是主链,数据包会 应用 该链的 默认策略,通常为 ACCEPT、DROP 等。
SNAT
该目标用于重写数据包 IP 头中的源 IP 地址。典型的场景是多台主机共享一个互联网连接。使用该目标以后,外面的数据包才知道应该返回给内网中的哪台主机。
该目标只适用于 nat 表格中的 POSTROUTING 链,这是唯一一条可以使用 SNAT 的链。只有连接的第一个数据包才会被 SNAT 修改,之后,随后使用该连接的所有数据包都会被进行相同的修改。
例:
iptables -t nat -A POSTROUTING -p tcp -o eth0 -j SNAT --to-source 194.236.50.155-194.236.50.160:1024-32000